计算服务器日志¶
计算节点上的日志,或运行 nova-compute 的任何服务器(例如在超融合架构中),是排查虚拟机管理程序和计算服务问题的首要位置。 此外,操作系统日志也可以提供有用的信息。
随着云环境的增长,日志数据的量呈指数级增加。 在 OpenStack 服务或操作系统上启用调试会进一步加剧数据问题。
日志记录在 日志记录和监控 中有更详细的描述。 然而,在开始云的运营之前,将它作为一个重要的设计考虑因素是至关重要的。
OpenStack 产生大量的有用日志信息,但为了使这些信息对运营目的有用,您应该考虑拥有一个中央日志服务器来接收日志,以及一个日志解析/分析系统,例如 Elastic Stack [以前称为 ELK]。
Elastic Stack 主要由三个组件组成:Elasticsearch(日志搜索和分析)、Logstash(日志摄取、处理和输出)和 Kibana(日志仪表板服务)。
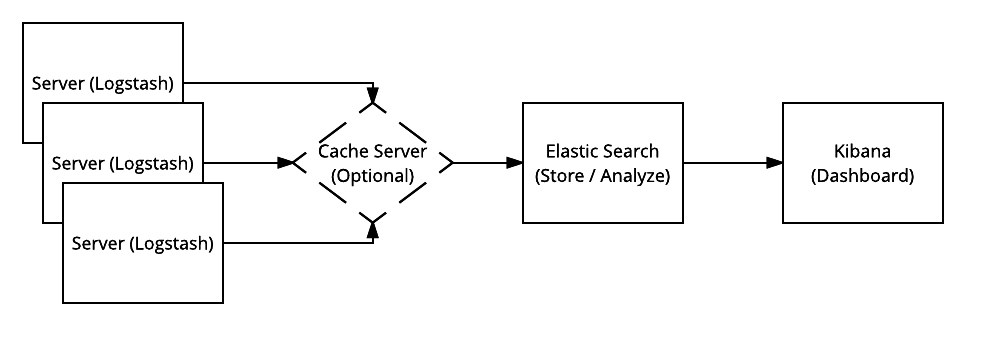
由于从 OpenStack 环境中的服务器发送的日志量很大,可以使用可选的内存数据结构存储。 常见的例子是 Redis 和 Memcached。 在较新版本的 Elastic Stack 中,一种名为 Filebeat 的文件缓冲区用于类似的目的,但在将数据发送到 Logstash 或 Elasticsearch 时增加了“反压敏感”协议。
日志分析通常需要不同格式的离散日志。 Elastic Stack(特别是 Logstash)旨在接收许多不同的日志输入,并将它们转换为 Elasticsearch 可以编目和分析的一致格式。 如上图所示,摄取过程从服务器上的 Logstash 开始,转发到 Elasticsearch 服务器进行存储和搜索,然后通过 Kibana 进行可视化分析和交互。
有关安装 Logstash、Elasticsearch 和 Kibana 的说明,请参阅 Elasticsearch 参考。
为了配置 Logstash 以用于 OpenStack,需要一些特定的配置参数。 例如,为了让 Logstash 收集、解析和将正确的日志文件部分发送到 Elasticsearch 服务器,您需要正确格式化配置文件。 有输入、输出和过滤器配置。 输入配置告诉 Logstash 从哪里接收数据(日志文件/转发器/filebeats/StdIn/Eventlog),输出配置指定将数据放置在何处,而过滤器配置定义要转发到输出的输入内容。
Logstash 过滤器对每个事件执行中间处理。 基于输入的特征和事件应用条件过滤器。 一些过滤示例是
grok
date
csv
json
还有可用的输出过滤器,可以将事件数据发送到许多不同的目的地。 一些例子是
csv
redis
elasticsearch
file
jira
nagios
pagerduty
stdout
此外,还有一些编解码器可用于更改事件的数据表示形式,例如
collectd
graphite
json
plan
rubydebug
这些输入、输出和过滤器配置通常存储在 /etc/logstash/conf.d 中,但可能因 Linux 发行版而异。 应该为不同的日志记录系统(例如 syslog、Apache 和 OpenStack)创建单独的配置文件。
可以在 Elastic 的 Logstash 配置页面 上找到常规示例和配置指南。
可以在 sorantis/elkstack 上找到 OpenStack 输入、输出和过滤器示例。
配置完成后,可以使用 Kibana 作为 OpenStack 和系统日志的可视化工具。 这将允许操作员为性能、监控和安全性配置自定义仪表板。
