CloudKitty 的架构¶
CloudKitty 可以划分为四个主要部分
数据检索 (API)
数据收集 (
cloudkitty-processor)数据评级
数据存储
这些部分由两个进程处理:cloudkitty-api 和 cloudkitty-processor。数据检索部分由 cloudkitty-api 进程处理,其他部分由 cloudkitty-processor 处理。
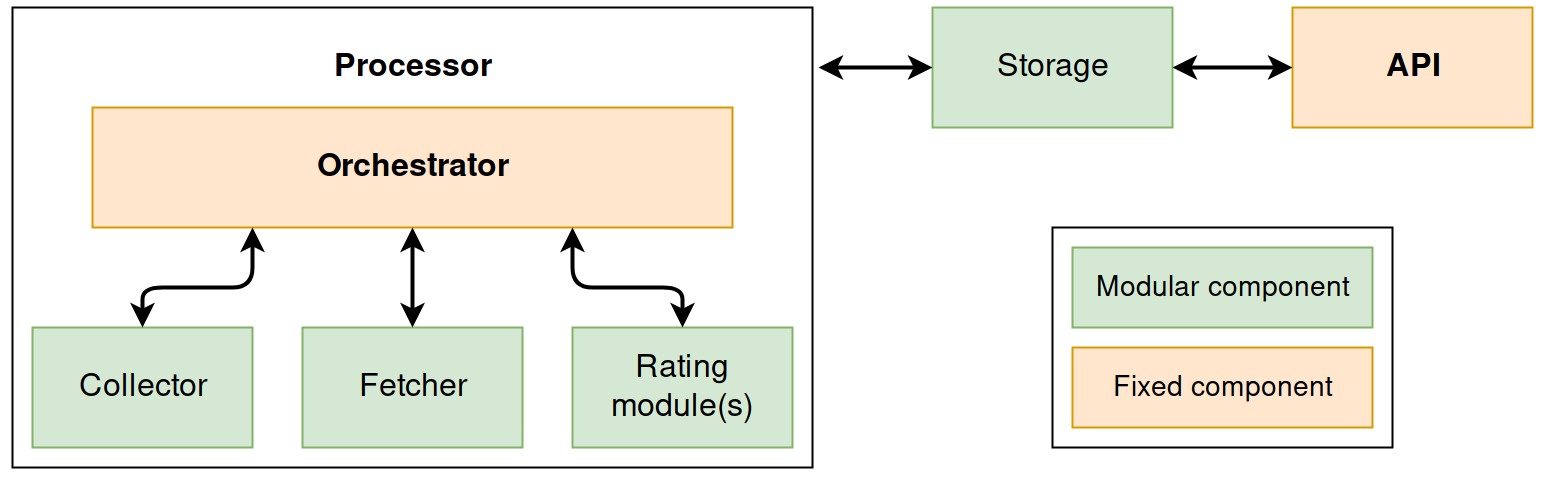
以下是 CloudKitty 架构的概述

有关 API 的详细信息,请参阅 api 参考
处理器包含以下部分
fetcher(提取器) 检索要评级的 **scopes(范围)** 列表。Scope 用于区分和隔离数据。它还允许在多个 cloudkitty-processor worker 之间分割工作负载。它可以是给定上下文中任何有意义的内容,例如 OpenStack 项目或 Kubernetes 命名空间。
collector(收集器) 为给定的 scope 和指标从源收集数据。
收集到的数据随后传递给 **rating modules(评级模块)**(可以同时启用多个模块)。这些模块将用户定义的评级规则应用于收集到的数据。
数据评级完成后,它将传递给 **storage driver(存储驱动程序)**,后者会将数据存储在给定的存储后端中。然后可以通过 API 访问此数据。
模块加载和扩展¶
CloudKitty 的几乎每个部分都使用 stevedore 来动态加载扩展。以下模式显示了模块化的部分
每个评级模块都在运行时加载,并且可以直接通过 CloudKitty 的 API 启用/禁用。该模块负责自己的 API,以便于管理其配置。
Collectors、fetchers 和存储后端在运行时加载,但必须在 CloudKitty 的配置文件中进行配置。
Fetcher(提取器)¶
CloudKitty 中有五个 fetcher 可用
keystonefetcher 从 Keystone 检索 cloudkitty 用户具有rating角色的项目列表。gnocchifetcher 为给定的资源类型从 Gnocchi 检索属性列表。这用于独立的 Gnocchi 部署,或在与 OpenStack 一起使用时发现 Gnocchi 中的新项目。它可以在 OpenStack 上下文中或与独立的 Gnocchi 部署一起使用。prometheusfetcher 的工作方式与 Gnocchi fetcher 类似,允许从 Prometheus 发现 scopes。sourcefetcher 是最简单的:它从配置文件中读取 scope 列表并将其提供给 collector。
有关每个 fetcher 配置的详细信息,请参阅 fetcher 配置指南。
Collector(收集器)¶
CloudKitty 中有三个 collector 可用
gnocchicollector 从 Gnocchi 检索数据。它可以在 OpenStack 上下文中或与独立的 Gnocchi 部署一起使用。prometheuscollector 从 Prometheus 检索数据。
有关每个 collector 配置的详细信息,请参阅 collector 配置指南。
有关如何编写自定义 collector 的信息,请参阅 开发者文档。
Rating(评级)¶
CloudKitty 中有两个评级模块可用(noop 不被认为是真正的模块,因为它不执行任何操作)。可以同时启用多个评级模块。数据将连续传递给启用的模块。可以通过 API 设置模块优先级,它决定了它们处理数据的顺序(优先级最高的模块首先处理)。
hashmap评级模块是最常用的模块。它允许基于指标元数据创建评级规则。pyscripts评级模块允许使用自定义 python 脚本对数据进行评级。
有关评级模块的使用和配置信息,请参阅 评级模块文档。
存储¶
存储模块负责将数据存储和检索到后端。它实现了两个接口(v1 和 v2),每个接口提供一个或多个驱动程序。有关存储后端的更多信息,请参阅 配置部分。
