扩展 MariaDB 和 RabbitMQ¶
OpenStack 是一个旨在高度可扩展的云计算平台。然而,即使 OpenStack 被设计为可扩展的,在大型部署中也可能出现一些潜在的瓶颈。这些瓶颈通常涉及 RabbitMQ 和 MariaDB 集群的性能和吞吐量。
RabbitMQ 是一个消息代理,用于解耦 OpenStack 的不同组件。MariaDB 是一个用于存储 OpenStack 数据的数据库。如果这两个组件的性能不佳,可能会对整个 OpenStack 部署的性能产生负面影响。
可以使用许多不同的方法来提高 RabbitMQ 和 MariaDB 集群的性能。这些方法包括扩展集群、使用不同的消息代理或数据库,或优化集群的配置。
在本系列文章中,将讨论大型 OpenStack 部署中可能出现的潜在瓶颈以及扩展部署以提高 RabbitMQ 和 MariaDB 集群性能的方法。
注意
本文档中提供的示例是在 OpenStack 2023.1 (Antelope) 上制作的。可以在较早的版本中实现相同的流程,但可能需要额外的步骤或略有不同的配置。
最常见的部署¶
在讨论如何改进方法之前,让我们快速描述一下“起点”,以便了解我们在起点处理的是什么。
最常见的 OpenStack-Ansible 部署设计是三个控制节点,每个节点都运行所有 OpenStack API 服务以及支持基础设施,如 MariaDB 和 RabbitMQ 集群。这对于小型到中型部署来说是一个很好的起点。但是,随着部署的增长,您可能会开始遇到性能问题。通常服务之间的通信以及与 MariaDB/RabbitMQ 的通信如下所示
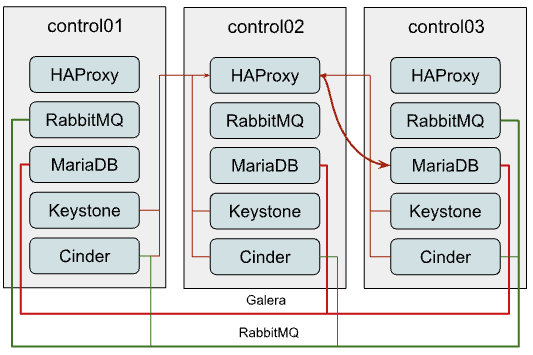
MariaDB
如您可能在图表中看到的那样,所有对 MariaDB 的连接都通过具有内部虚拟 IP (VIP) 的 HAProxy。OpenStack-Ansible 会为 MariaDB 配置 Galera 集群,这是一个多主复制系统。虽然您可以将任何请求发送到集群的任何成员,但所有写入请求都将传递到当前的“主”实例,从而创建更多的内部流量并增加每个实例应该处理的工作量。因此,建议仅将写入请求发送到“主”实例。
但是,HAProxy 无法在应用程序级别(OSI 模型的 L7)平衡 MariaDB 查询,以分离读写请求,因此我们必须平衡 TCP 流(L3)并将所有流量在没有任何分离的情况下传递到 Galera 集群中的当前“主”节点,这会产生潜在的瓶颈。
RabbitMQ
RabbitMQ 的集群方式不同。我们将集群所有成员的 IP 地址提供给客户端,由客户端决定使用哪个后端进行交互。只有 RabbitMQ 管理 UI 通过 HAProxy 进行平衡,因此客户端与队列的连接不以任何方式依赖于 HAProxy。
虽然使用 HA 队列甚至 Quorum 队列会将所有消息和队列镜像到所有或几个集群成员。虽然 Quorum 队列显示出更好的性能,但它们仍然会受到集群流量的影响,这在一定规模下仍然会成为一个问题。
选项 1:每个服务独立的集群¶
使用这种方法,您可以为 Nova 或 Neutron 等负载最高的服务提供独立的 MariaDB 和 RabbitMQ 集群。这些新的集群可以驻留在单独的硬件上。
在下面的示例中,我们假设只有 Neutron 被重新配置为使用新的独立集群,而其他服务仍然共享现有的集群。因此 Neutron 的连接如下所示
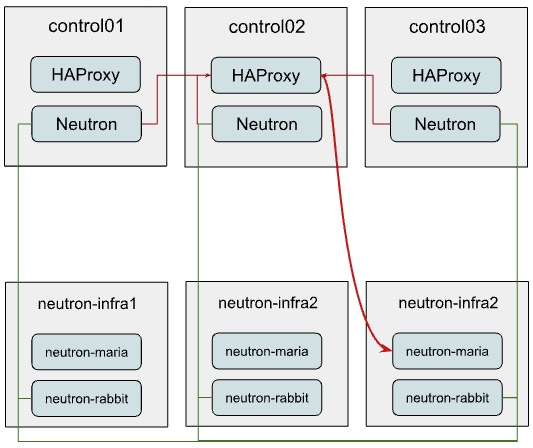
如您所见,我们仍然使用相同的 HAProxy 实例来平衡到新的基础设施集群的 MariaDB。
接下来,我们将描述如何配置这样的堆栈并执行服务过渡到这种新的布局。
设置新的 MariaDB 和 RabbitMQ 集群¶
要配置这样的布局并使用 OpenStack-Ansible 迁移 Neutron,您需要遵循以下步骤
注意
您可以参考以下文档以更深入地了解如何构建 env.d 和 conf.d 文件:了解清单
为 RabbitMQ 和 MariaDB 定义新的组。为此,您可以创建包含以下内容的文件:
/etc/openstack_deploy/env.d/galera-neutron.yml# env.d file are more clear if you read them bottom-up # At component skeleton you map component to ansible groups component_skel: # Component itself is an ansible group as well neutron_galera: # You tell in which ansible groups component will appear belongs_to: - neutron_galera_all - galera_all # At container skeleton you link components to physical layer container_skel: neutron_galera_container: # Here you define on which physical hosts container will reside belongs_to: - neutron-database_containers # Here you define which components will reside on container contains: - neutron_galera # At physical skeleton level you map containers to hosts physical_skel: # Here you tell to which global group containers will be added # from the host in question. # Please note, that <name>_hosts and <name>_containers are # interconnected, and <name> can not contain underscores. neutron-database_containers: belongs_to: - all_containers # You define `<name>_hosts` in your openstack_user_config or conf.d # files to tell on which physical hosts containers should be spawned neutron-database_hosts: belongs_to: - hosts
/etc/openstack_deploy/env.d/rabbit-neutron.yml:# On the component level we are creating group `neutron_rabbitmq` # that is also part of `rabbitmq_all` and `neutron_rabbitmq_all` component_skel: neutron_rabbitmq: belongs_to: - rabbitmq_all - neutron_rabbitmq_all # On the container level we tell to create neutron_rabbitmq on # neutron-mq_hosts container_skel: neutron_rabbit_mq_container: belongs_to: - neutron-mq_containers contains: - neutron_rabbitmq # We define the physical level as a base level which can be consumed # by container and component skeleton. physical_skel: neutron-mq_containers: belongs_to: - all_containers neutron-mq_hosts: belongs_to: - hosts
将您的新 neutron-infra 主机映射到这些新组。要添加到您的 openstack_user_config.yml,请添加以下内容
neutron-mq_hosts: &neutron_infra
neutron-infra1:
ip: 172.29.236.200
neutron-infra2:
ip: 172.29.236.201
neutron-infra3:
ip: 172.29.236.202
neutron-database_hosts: *neutron_infra
为新创建的组定义一些特定的配置并平衡它们
MariaDB
在文件
/etc/openstack_deploy/group_vars/neutron_galera.ymlgalera_cluster_members: "{{ groups['neutron_galera'] }}" galera_cluster_name: neutron_galera_cluster galera_root_password: mysecret
在文件 /etc/openstack_deploy/group_vars/galera.yml
galera_cluster_members: "{{ groups['galera'] }}"
将 galera_root_password 从
/etc/openstack_deploy/user_secrets.yml移动到/etc/openstack_deploy/group_vars/galera.ymlRabbitMQ
在文件
/etc/openstack_deploy/group_vars/neutron_rabbitmq.yml
rabbitmq_host_group: neutron_rabbitmq rabbitmq_cluster_name: neutron_cluster
在文件
/etc/openstack_deploy/group_vars/rabbitmq.yml
rabbitmq_host_group: rabbitmq
HAProxy
在
/etc/openstack_deploy/user_variables.yml中为 MariaDB 定义额外的服务
haproxy_extra_services: - haproxy_service_name: galera_neutron haproxy_backend_nodes: "{{ (groups['neutron_galera'] | default([]))[:1] }}" haproxy_backup_nodes: "{{ (groups['neutron_galera'] | default([]))[1:] }}" haproxy_bind: "{{ [haproxy_bind_internal_lb_vip_address | default(internal_lb_vip_address)] }}" haproxy_port: 3307 haproxy_backend_port: 3306 haproxy_check_port: 9200 haproxy_balance_type: tcp haproxy_stick_table_enabled: False haproxy_timeout_client: 5000s haproxy_timeout_server: 5000s haproxy_backend_options: - "httpchk HEAD / HTTP/1.0\\r\\nUser-agent:\\ osa-haproxy-healthcheck" haproxy_backend_server_options: - "send-proxy-v2" haproxy_allowlist_networks: "{{ haproxy_galera_allowlist_networks }}" haproxy_service_enabled: "{{ groups['neutron_galera'] is defined and groups['neutron_galera'] | length > 0 }}" haproxy_galera_service_overrides: haproxy_backend_nodes: "{{ groups['galera'][:1] }}" haproxy_backup_nodes: "{{ groups['galera'][1:] }}"
准备新的基础设施主机并在其上创建容器。为此,运行命令
# openstack-ansible playbooks/setup-hosts.yml --limit neutron-mq_hosts,neutron-database_hosts,neutron_rabbitmq,neutron_galera
部署集群
MariaDB
openstack-ansible playbooks/galera-install.yml --limit neutron_galeraRabbitMQ
openstack-ansible playbooks/rabbitmq-install.yml --limit neutron_rabbitmq
迁移服务以使用新的集群¶
虽然开始使用新的 RabbitMQ 集群对于服务来说相对容易,但数据库的迁移稍微复杂一些,并且会包含一些停机时间。
首先,我们需要告诉 Neutron,从现在开始,服务的 MariaDB 数据库正在侦听不同的端口。因此,您应该将以下覆盖添加到您的 user_variables.yml
neutron_galera_port: 3307
现在让我们准备目标数据库:创建数据库本身以及所需的用户,并向他们提供与数据库交互的权限。为此,我们将使用带有 common-db 标签的 neutron 角色,并仅将执行限制在 neutron_server 组。您可以使用以下命令
# openstack-ansible playbooks/os-neutron-install.yml --limit neutron_server --tags common-db
一旦准备好数据库,我们需要禁用代理到服务 API 的 HAProxy 后端,以防止任何用户或服务操作。
为此,我们使用一个小的自定义 playbook。让我们将其命名为 haproxy_backends.yml
- hosts: haproxy_all
tasks:
- name: Manage backends
community.general.haproxy:
socket: /run/haproxy.stat
backend: "{{ backend_group }}-back"
drain: "{{ haproxy_drain | default(False) }}"
host: "{{ item }}"
state: "{{ haproxy_state | default('disabled') }}"
shutdown_sessions: "{{ haproxy_shutdown_sessions | default(False) | bool }}"
wait: "{{ haproxy_wait | default(False) | bool }}"
wait_interval: "{{ haproxy_wait_interval | default(5) }}"
wait_retries: "{{ haproxy_wait_retries | default(24) }}"
with_items: "{{ groups[backend_group] }}"
我们这样运行它
# openstack-ansible haproxy_backends.yml -e backend_group=neutron_server
现在,我们可以停止 Neutron 的 API 服务
# ansible -m service -a "state=stopped name=neutron-server" neutron_server
然后运行服务 MariaDB 数据库的备份/还原。为此,我们将使用另一个小的 playbook,我们将其命名为 mysql_backup_restore.yml,内容如下
- hosts: "{{ groups['galera'][0] }}"
vars:
_db: "{{ neutron_galera_database | default('neutron') }}"
tasks:
- name: Dump the db
shell: "mysqldump --single-transaction {{ _db }} > /tmp/{{ _db }}"
- name: Fetch the backup
fetch:
src: "/tmp/{{ _db }}"
dest: "/tmp/db-backup/"
flat: yes
- hosts: "{{ groups['neutron_galera'][0] }}"
vars:
_db: "{{ neutron_galera_database | default('neutron') }}"
tasks:
- name: Copy backups to destination
copy:
src: "/tmp/db-backup/"
dest: "/tmp/db-backup/"
- name: Restore the DB backup
shell: "mysql {{ _db }} < /tmp/db-backup/{{ _db }}"
现在让我们运行我们刚刚创建的 playbook
# openstack-ansible mysql_backup_restore.yml
注意
上面的 playbook 不是幂等的,因为它将覆盖目标主机上的数据库内容。
一旦数据库内容到位,我们现在可以使用 playbook 重新配置服务。
它不仅会告诉 Neutron 使用新的数据库,还会将其切换到使用新的 RabbitMQ 集群,并在 HAProxy 中重新启用该服务。
为此,我们应该运行以下命令
# openstack-ansible playbooks/os-neutron-install.yml --tags neutron-config,common-mq
playbook 完成后,neutron 服务将启动并配置为使用新的集群。
选项 2:集群专用硬件¶
此选项将描述如何将当前的 MariaDB 和 RabbitMQ 集群移动到独立节点。这种方法可用于卸载控制平面并为集群提供专用资源。
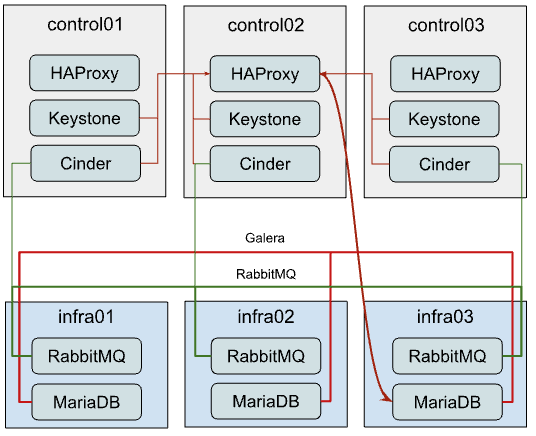
虽然从部署一开始就建立上述架构非常简单,但将现有部署无缝迁移到这种设置更加复杂,因为您需要将正在运行的集群迁移到新硬件。由于我们将逐个执行,以保留至少两个活动的集群成员,因此以下步骤应针对其他两个成员重复。
将 MariaDB 迁移到新硬件¶
首先要做的是列出 MariaDB 集群的当前成员。为此,您可以发出以下临时命令
# cd /opt/openstack-ansible/
# ansible -m debug -a "var=groups['galera']" localhost
localhost | SUCCESS => {
"groups['galera']": [
"control01_galera_container-68e1fc47",
"control02_galera_container-59576533",
"control03_galera_container-f7d1b72b"
]
}
除非被覆盖,否则该组中的第一个主机被认为是“bootstrap”主机。应最后迁移此 bootstrap 主机,以避免不必要的故障转移,因此建议从输出中的最后一个主机到第一个主机开始迁移到新硬件。
一旦我们确定了执行顺序,就该进行逐步指南了。
使用以下 playbook 删除组中的最后一个容器
# openstack-ansible playbooks/lxc-containers-destroy.yml --limit control03_galera_container-f7d1b72b
从清单中清理删除的容器
# ./scripts/inventory-manage.py -r control03_galera_container-f7d1b72b
重新配置 openstack_user_config 以创建新的容器。
假设您当前在您的 openstack_user_config.yml 中有如下配置
_control_hosts: &control_hosts control01: ip: 172.29.236.11 control02: ip: 172.29.236.12 control03: ip: 172.29.236.13 shared-infra_hosts: *control_hosts
将其转换为如下所示
_control_hosts: &control_hosts control01: ip: 172.29.236.11 control02: ip: 172.29.236.12 control03: ip: 172.29.236.13 memcaching_hosts: *control_hosts mq_hosts: *control_hosts operator_hosts: *control_hosts database_hosts: control01: ip: 172.29.236.11 control02: ip: 172.29.236.12 infra03: ip: 172.29.236.23
在上面的示例中,我们将 shared-infra_hosts 的每个部分解耦,并单独定义它们,同时为 MariaDB 提供新的目标主机。
在新基础设施节点上创建容器
# openstack-ansible playbooks/lxc-containers-create.yml --limit infra03,galera
注意
新的基础设施主机应在此步骤之前准备好(例如,通过对它们运行
setup-hosts.ymlplaybook)。在此处安装 MariaDB 并将其添加到集群
# openstack-ansible playbooks/galera-install.yml
playbook 完成后,您可以使用以下临时命令确保集群处于 Synced 状态并具有适当的 cluster_size
# ansible -m command -a "mysql -e \"SHOW STATUS WHERE Variable_name IN ('wsrep_local_state_comment', 'wsrep_cluster_size', 'wsrep_incoming_addresses')\"" neutron_galera
如果集群正常,请对其余实例重复步骤 1-6,包括“bootstrap”实例。
将 RabbitMQ 迁移到新硬件¶
RabbitMQ 的迁移过程与 MariaDB 几乎相同,只有一个例外 - 我们需要在将它们移动到新硬件时保留容器的相同 IP 地址。否则,我们需要重新配置所有依赖 RabbitMQ 的服务(如 cinder、nova、neutron 等),因为与通过 HAProxy 平衡的 MariaDB 不同,客户端决定连接到哪个 RabbitMQ 后端。
因此,我们也不关心迁移顺序。
由于我们需要保留 IP 地址,让我们在对当前设置采取任何操作之前收集此数据
# ./scripts/inventory-manage.py -l | grep rabbitmq
| control01_rabbit_mq_container-a3a802ac | None | rabbitmq | control01 | None | 172.29.239.49 | None |
| control02_rabbit_mq_container-51f6cf7c | None | rabbitmq | control02 | None | 172.29.236.82 | None |
| control03_rabbit_mq_container-b30645d9 | None | rabbitmq | control03 | None | 172.29.238.23 | None |
在删除 RabbitMQ 容器之前,值得将 RabbitMQ 实例转换为维护模式,以便它可以将其职责卸载到其他集群成员并正确关闭与客户端的连接。您可以使用以下临时命令
root@deploy:/opt/openstack-ansible# ansible -m command -a "rabbitmq-upgrade drain" control01_rabbit_mq_container-a3a802ac
control01_rabbit_mq_container-a3a802ac | CHANGED | rc=0 >>
Will put node rabbit@control01-rabbit-mq-container-a3a802ac into maintenance mode. The node will no longer serve any client traffic!
现在我们可以继续进行容器删除
# openstack-ansible playbooks/lxc-containers-destroy.yml --limit control01_rabbit_mq_container-a3a802ac
并从清单中删除它
# ./scripts/inventory-manage.py -r control01_rabbit_mq_container-a3a802ac
现在您需要重新配置 openstack_user_config,类似于 MariaDB 的操作方式。在此阶段,RabbitMQ 的结果记录应如下所示
mq_hosts: infra01: ip: 172.29.236.21 control02: ip: 172.29.236.12 control03: ip: 172.29.236.13
注意
确保您没有定义更多的通用 shared-infra_hosts。
现在我们需要手动重新生成清单并确保将新记录映射到我们的 infra01
# ./inventory/dynamic_inventory.py
...
# ./scripts/inventory-manage.py -l | grep rabbitmq
| control02_rabbit_mq_container-51f6cf7c | None | rabbitmq | control02 | None | 172.29.236.82 | None |
| control03_rabbit_mq_container-b30645d9 | None | rabbitmq | control03 | None | 172.29.238.23 | None |
| infra01_rabbit_mq_container-10ec4732 | None | rabbitmq | infra01 | None | 172.29.238.248 | None |
如上面的输出所示,已生成一个记录并正确分配给 infra01 主机。虽然此容器具有新的 IP 地址,但我们需要保留它。因此,我们手动将清单文件中的新 IP 替换为旧 IP,并确保现在它是正确的
# sed -i 's/172.29.238.248/172.29.239.49/g' /etc/openstack_deploy/openstack_inventory.json
#./scripts/inventory-manage.py -l | grep rabbitmq
| control02_rabbit_mq_container-51f6cf7c | None | rabbitmq | control02 | None | 172.29.236.82 | None |
| control03_rabbit_mq_container-b30645d9 | None | rabbitmq | control03 | None | 172.29.238.23 | None |
| infra01_rabbit_mq_container-10ec4732 | None | rabbitmq | infra01 | None | 172.29.239.49 | None |
现在您可以继续创建容器
# openstack-ansible playbooks/lxc-containers-create.yml --limit infra01,rabbitmq
并在新容器上安装 RabbitMQ 并确保它是集群的一部分
# openstack-ansible playbooks/rabbitmq-install.yml
一旦集群重新建立,值得使用有关旧容器名称仍然被视为“Disk Node”的集群状态进行清理
# ansible -m command -a "rabbitmqctl forget_cluster_node rabbit@control01-rabbit-mq-container-a3a802ac" rabbitmq[0]
注意
您可以从步骤二的输出中获取要删除的集群节点名称。
对其余实例重复上述步骤。
选项 3:水平扩展集群¶
这个选项到目前为止是最不受欢迎的,尽管它非常简单,因为它具有相当狭窄的使用案例,在这种情况下才有意义以这种方式扩展。
但是,为了保持仲裁,您应该始终拥有奇数个集群成员,或者准备好在使用的成员数为偶数时提供额外的配置。
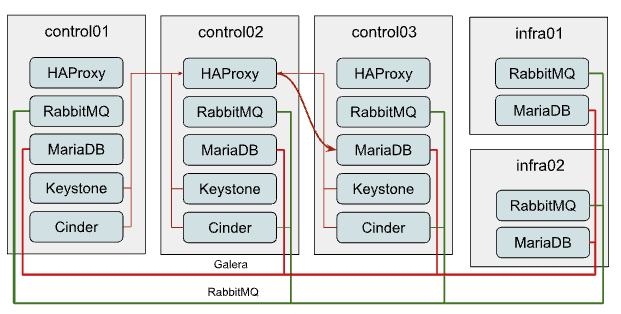
向 MariaDB Galera 集群添加新成员¶
水平扩展 MariaDB 集群只有在您使用可以与 Galera 集群配合使用(如 ProxySQL 或 MaxScale)的 L7 负载均衡器而不是默认的 HAProxy 并且当前集群的瓶颈是读取性能而不是写入性能时才有意义。
扩展集群非常简单。为此,您需要
在
openstack_user_config中为 database_hosts 添加另一个目标主机database_hosts: control01: ip: 172.29.236.11 control02: ip: 172.29.236.12 control03: ip: 172.29.236.13 infra01: ip: 172.29.236.21 infra02: ip: 172.29.236.22
在新主机上创建容器
# openstack-ansible playbooks/lxc-containers-create.yml --limit infra01,infra02,galera
在那里部署 MariaDB 并将其添加到集群
# openstack-ansible playbooks/galera-install.yml
使用以下临时命令确保集群正常
# ansible -m command -a "mysql -e \"SHOW STATUS WHERE Variable_name IN ('wsrep_local_state_comment', 'wsrep_cluster_size', 'wsrep_incoming_addresses')\"" neutron_galera
向 RabbitMQ 集群添加新成员¶
垂直扩展 RabbitMQ 集群在您没有启用 HA 队列或 Quorum 队列时才有意义。
要向 RabbitMQ 集群添加更多成员,请执行以下步骤
在
openstack_user_config中为 mq_hosts 添加另一个目标主机mq_hosts: control01: ip: 172.29.236.11 control02: ip: 172.29.236.12 control03: ip: 172.29.236.13 infra01: ip: 172.29.236.21 infra02: ip: 172.29.236.22
在新主机上创建容器
# openstack-ansible playbooks/lxc-containers-create.yml --limit infra01,infra02,rabbitmq
在新主机上部署 RabbitMQ 并将其注册到集群
# openstack-ansible playbooks/rabbitmq-install.yml
一旦部署了新的 RabbitMQ 容器,您需要通过重新配置所有服务(如 neutron、nova、cinder 等)来让所有服务意识到它的存在。为此,您可以运行单个服务 playbook,如下所示
# openstack-ansible playbooks/os-<service>-install.yml –tags <service>-config
其中 <service> 是服务名称,如 neutron、nova、cinder 等。另一种方法是启动 setup-openstack.yml,但执行时间会很长。
结论¶
正如您可能看到的,OpenStack-Ansible 具有足够的灵活性,可以让你以多种不同的方式扩展部署。
但是,哪一种适合你呢?嗯,这完全取决于你所处的具体情况。
如果你的部署已经发展到 RabbitMQ/MariaDB 集群无论底层硬件如何都无法处理它们产生的负载,那么你应该使用选项一 (选项 1:为每个服务使用独立的集群),并为每个服务创建独立的集群。
这个选项也可以推荐用于提高部署的弹性——如果集群发生故障,只会影响一个服务,而不是常见部署场景中的所有服务。 这个选项的另一个流行变体是为每个服务只使用独立的 MariaDB/RabbitMQ 实例,而无需任何集群化。 这种设置的好处是恢复速度非常快,尤其是在谈到 RabbitMQ 时。
如果你拥有的控制器硬件规格比较低,你可能需要更加关注选项二 (选项 1:为每个服务使用独立的集群)。 这样可以将 MariaDB/RabbitMQ 等占用大量资源的应用程序卸载到其他硬件上,这些硬件也可以具有相对较低的规格。
如果你的部署满足上述要求(即不使用 HA 队列或使用 ProxySQL 进行负载均衡),并且通常应该在你已经超出选项一的范围后考虑选项三 (选项 3:水平扩展集群)。
