动态代码模式:使用插件扩展您的应用程序¶
在过去的几年里,我一直在研究大量大量使用 Python 在运行时动态加载代码的应用程序。本文包括了我对使用动态代码模式的一些专注研究结果,以及这些研究对 stevedore 和使用它的应用程序 ceilometer 的设计所产生的影响。
为了进行分析,我将任何在运行时动态加载代码的应用程序或框架都视为使用了插件。我没有将硬编码导入语句的延迟执行视为插件,而是将研究限制在真正的动态加载。在大多数情况下,代码的名称或位置是通过诸如配置文件之类的外部机制提供的。
为什么要使用插件?¶
在检查使用插件的模式之前,我们应该先谈谈为什么要在应用程序中使用插件。
一个重要的好处是改进设计。保持核心代码和扩展代码的分离,会促使您更多地考虑设计中的抽象。构建一个可扩展的系统可能比硬编码一切需要更多的工作,但从长远来看,结果通常会更灵活、更易于维护。
插件是实现设备驱动程序和其他 策略模式 变体的良好方式。应用程序可以维护通用的核心逻辑,而插件可以处理与外部系统或设备接口的细节。
单独打包扩展可以减少依赖臃肿,并使部署更容易管理和安装。不需要某些驱动程序或功能的用户的部署可以避免安装仅由这些插件使用的依赖项。
通过将新代码挂接到明确定义的扩展点,插件还提供了一种方便的方式来扩展应用程序的功能集。拥有这样一个可扩展的系统,可以使其他开发人员更容易通过提供单独发布的附加包来间接贡献您的项目。
Ceilometer 的要求¶
在帮助创建 ceilometer(OpenStack 的新计量组件)的一年中,我花了相当多的时间研究基于插件的架构。Ceilometer 测量云部署中使用的资源,以便我们可以为租户对这些资源进行计费。我们收集服务器生命周期、带宽和存储消耗等数据。
然而,给定云部署者想要收费的事物的类型和数量会有所不同,因此我们需要一个灵活的系统来获取这些测量结果。我们需要允许部署者编写自己的插件来测量我们尚未想到但可能需要以其配置私有方式衡量的东西(我们在 DreamHost 就遇到了这种情况)。
我们预计会有许多不直接与我们互动的发展者试图为 ceilometer 编写扩展,以便在私有云部署中使用,因此清楚地记录如何创建新插件也很重要。
考虑到这些因素,我们将 ceilometer 设计为在几个不同领域具有灵活性。
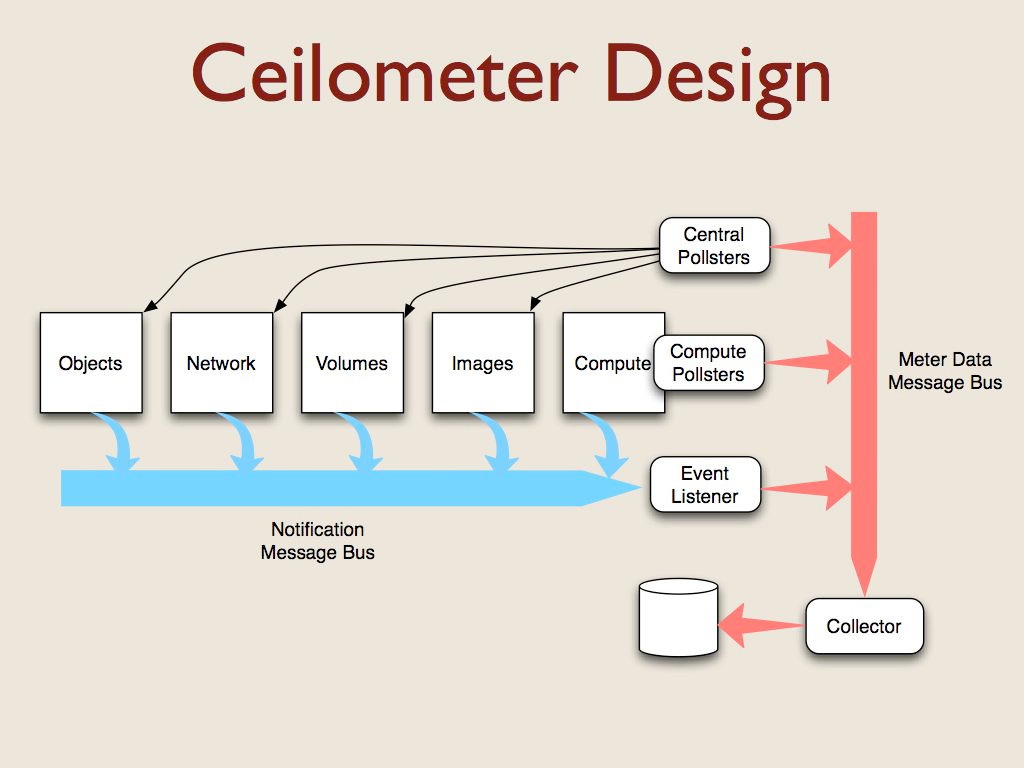
OpenStack 是一个组件集合,它们协同工作以提供 基础设施即服务 功能。每个组件管理云的不同方面,并使用消息总线与其他组件进行通信。
当事件发生时(例如实例的创建或销毁),所有组件都会生成通知消息。捕获这些消息是 ceilometer 的第一个数据源。通知包含不同的元数据,具体取决于触发事件的资源,因此我们需要插件将通知消息翻译成标准格式以进行计量。
并非所有我们想要为计费进行衡量的东西都有事件,所以我们还必须创建一些代理来轮询数据。例如,我们想定期检查每个实例消耗了多少 CPU 容量。一些轮询器运行在虚拟机管理程序服务器上,另一些运行在管理服务器上,在那里它们可以通过 API 与其他 OpenStack 组件通信。
所有 ceilometer 服务都使用另一个消息总线将数据传递给收集器进程,该进程使用存储驱动程序将数据写入数据库。我们支持关系型和非关系型数据库,具体取决于部署者的选择。
此架构产生了 ceilometer 的五组插件。OpenStack 包括一个消息总线抽象层以及一套用于使用 RabbitMQ、Qpid 和 ZMQ 的驱动程序。由于这些已经为我们实现,所以我们不必去处理它们。
我们从头开始创建了其他 4 组
用于处理通知消息的插件
计算节点的轮询器
中央轮询器
以及存储驱动程序
最终的设计使用了在其他使用插件的应用程序和框架中发现的模式。
其他基于插件的应用程序¶
在我的研究中,我查看了一些我作为用户或开发人员已经熟悉的项目,以及一些我以前没有用过的项目。有很多其他例子,但这个列表已经足够长,可以识别出一些常见的模式并帮助我们进行设计。
Blogofile 和 Sphinx 是用于处理不同形式文本以进行发布的两个应用程序。它们使用扩展来添加新的内容处理功能。
Mercurial 是一个命令行应用程序,可以通过新的子命令进行扩展。 Cliff 是我为构建 Mercurial 等应用程序而创建的一个库。
Virtualenvwrapper 是一个命令行工具,它以不同的方式使用钩子来扩展现有命令,但不一定添加新命令。
Nose 和 Trac 是常见的开发人员工具。您更可能使用它们而不是为它们编写扩展,但它们都使用插件。
Django、Pyramid 和 SQLAlchemy 是使用插件的开发人员库。
Diamond 是一个具有广泛插件集的监控应用程序,类似于我们计划为 OpenStack 构建的系统。
Nova 是 OpenStack 云系统的主要组件。它依赖于大量驱动程序来管理计算环境的不同方面。
我查看了所有这些代码,试图为 ceilometer 的插件找到“正确的方法”。虽然我今天说的一些话可能听起来是在批评其他代码开发人员所做的选择,但我确实拥有事后诸葛亮的优势,并且由于同时查看了所有示例以及我们项目不同的需求,因此拥有不同的视角。
发现¶
应用程序与插件打交道的第一个步骤是找到它。我查看的工具在显式定义插件的某种形式和查找插件的扫描器之间进行了划分。
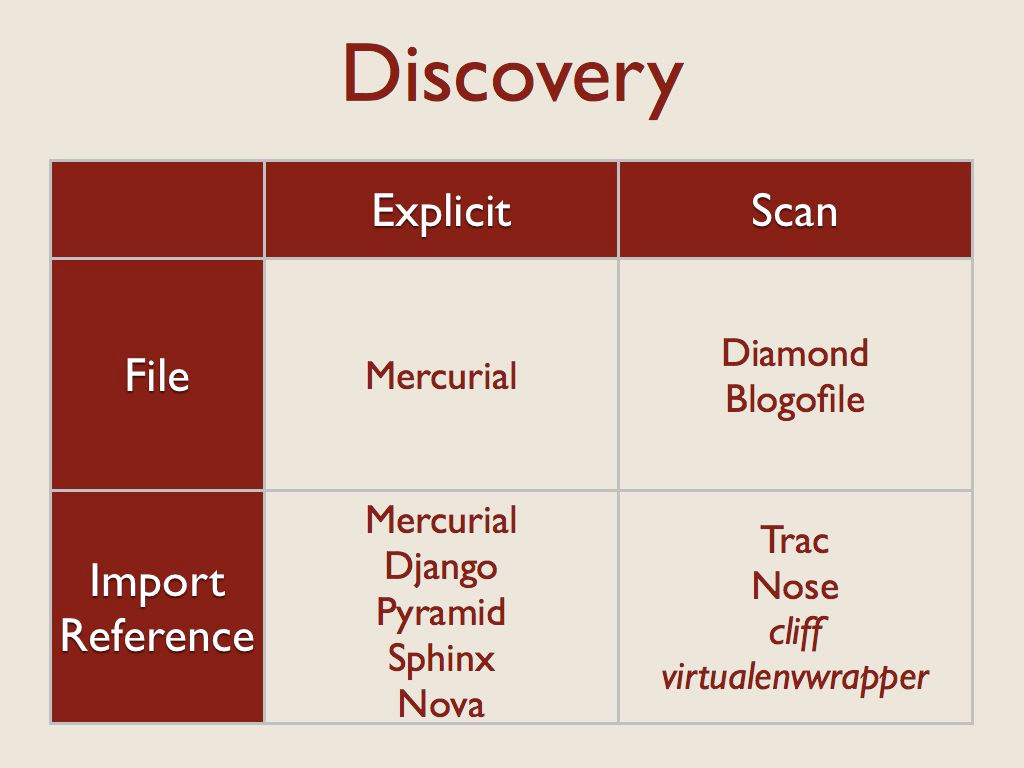
每一组又进一步分为正在列出或扫描的内容——文件系统上的文件,或 Python 导入引用(模块或模块内的某个内容)。
“显式导入引用”类别意味着某处有一个配置文件,用户在该文件中列出了一个可导入的对象。
“扫描导入引用”类别意味着正在扫描导入字符串的注册表。所有这些示例都使用 setuptools 和 pkg_resources 来管理入口点。
启用¶
在应用程序找到插件后,下一步是决定是否加载并使用它。大多数应用程序都需要一个显式步骤来配置扩展。有时这样做是有意义的。Django 等开发工具要求开发人员显式列出所需的扩展是正确的,因为您实际上是以静态方式引入该代码的。SQLAlchemy 的扩展都已启用,但一次实际上只使用一个,而这由数据库连接字符串选择。

然而,一些用户应用程序,如 Blogofile、Mercurial 和 Trac,要求用户通过配置步骤显式启用扩展,这似乎是可以跳过的。当我创建 virtualenvwrapper 和 cliff 时,我决定使用安装作为激活的触发器,因为我想避免额外的误配置机会。在这两种情况下,安装扩展都可以使其可用,因此用户可以立即开始利用它。
Nose 扩展也是如此,尽管它们是否用于给定的测试套件或测试运行取决于您为 nose 提供的选项。
导入¶
在应用程序决定是否加载插件之后,下一步是实际获取代码。我查看的所有示例都使用了两种技术:调用 import(通过使用内置函数、imp 模块或其他变体),或者使用 pkg_resources。

Nose、SQLAlchemy 和 Blogofile 都同时使用了这两种技术。如果未安装 pkg_resources,Nose 会回退到自定义导入器。SQLAlchemy 为随核心分发的“扩展”使用自定义导入器,但使用 pkg_resources 来查找单独的包。Blogofile 使用 pkg_resources 来查找插件,并结合手动扫描和导入包含这些插件的目录来加载它们的部件。
如果我忽略了我自己创建的包(这里用斜体显示),似乎有一个明显的趋势是创建围绕 import 的自定义包装器。这种方法起初看起来很容易,但我发现的所有实现都在棘手的边缘情况下表现出一些问题。
应用程序/插件集成¶
在导入了扩展代码之后,下一步是将其集成到应用程序的其余部分。也就是说,配置任何需要调用插件的钩子,将插件所需的任何状态传递给它,等等。我从两个维度考察了这一步。
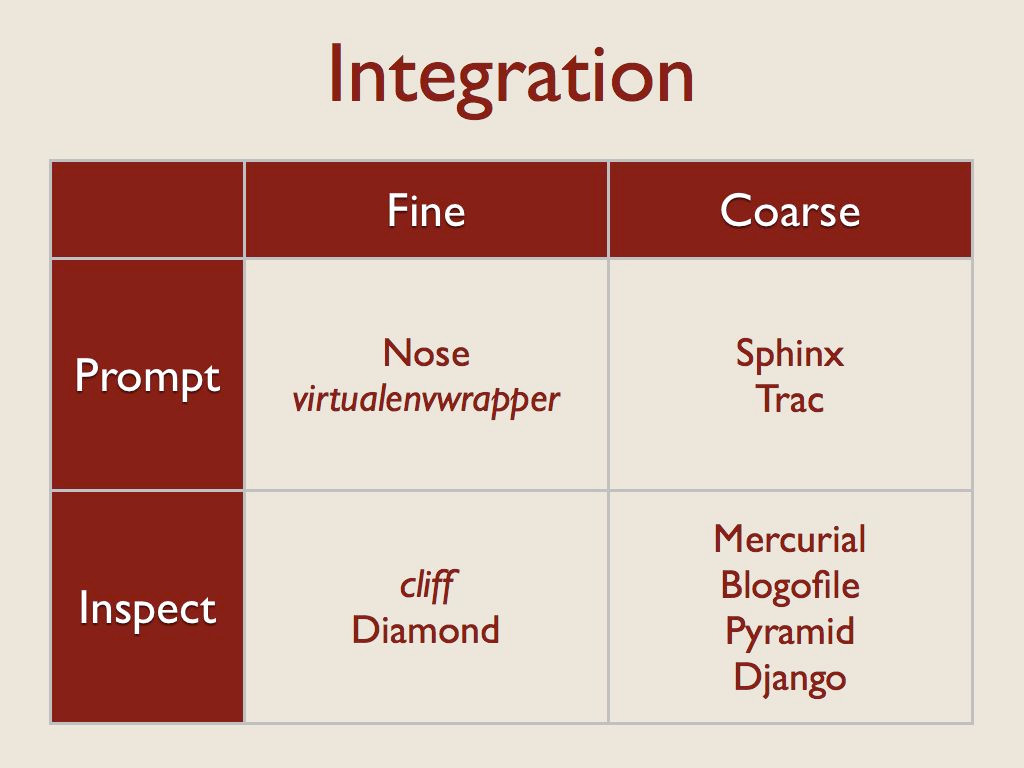
首先,我考虑了插件接口的粒度。对于“细粒度”插件,扩展被视为一个独立的 [object],在需要时对其进行调用。在这些情况下,被加载的代码对象通常是函数或类。
对于更“粗粒度”的情况,单个插件将包含在应用程序的多个位置引用的钩子。例如,插件内可能包含多个类,或者应用程序直接访问的模板,而不是通过插件 API 访问。
与集成相关的另一个维度是插件提供的代码如何被引入应用程序。我发现了两种技术。
首先,应用程序可以指示插件自行集成。这种提示通常采用插件作者实现的 setup() 或 initialization 函数的形式,该函数会回调应用程序上下文对象,显式注册插件的各个部分。也可以使用像 Trac 使用 zope.interface 这样的接口库来隐式处理这种注册。
其次,应用程序本身可以审视或检查插件,并根据结果做出决定。这通常意味着插件 API 的一部分负责提供有关插件本身的元数据,而不仅仅是采取行动。
API 强制执行¶
动态加载代码的一个常见问题是在运行时强制执行插件 API。这在动态语言中始终是一个潜在的问题,但它经常出现在插件中,因为代码通常是由应用程序的核心开发人员以外的人编写的。我看到了两种基本技术来帮助开发人员正确编写插件:约定和接口。
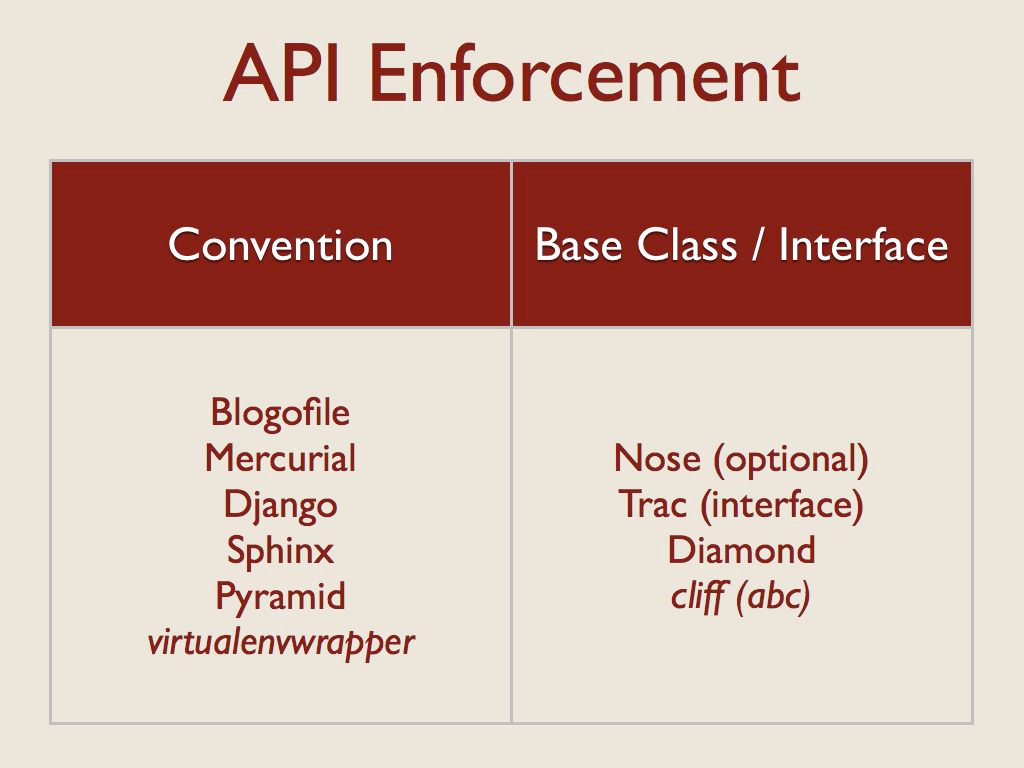
许多使用约定的应用程序也具有粗粒度的插件 API,因此虽然它们可能使用类来提供其功能,但插件依赖于约定来发现其配置。
右侧是使用类层次结构的插件的应用程序。对于 Nose,使用基类是可选的,因此它是一个准接口。另一方面,Trac 通过 zope.interface 使用正式接口。
Diamond 强制严格继承其 Collector 基类。
对于 cliff,我选择使用 abc 模块来定义抽象基类,但在实际应用程序中坚持使用 “鸭子类型”。开发人员不必继承基类,但这样做有助于确保实现完整。
调用¶
我研究的最后一个维度是如何在运行时使用插件代码。这里有三种主要的模式。
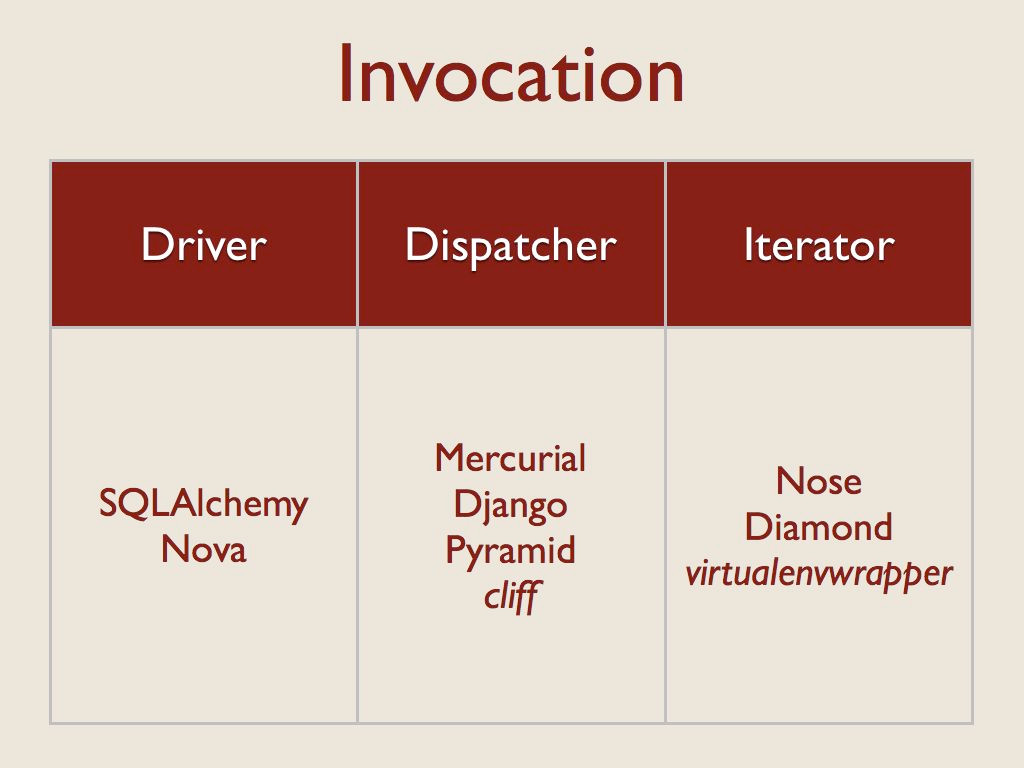
“驱动程序”一次加载一个,并直接使用。
使用“调度程序”模式的应用程序会加载所有扩展,然后在事件发生时根据名称或其他选择标准调用适当的扩展。
使用“迭代器”模式的应用程序会依次调用每个扩展,以便所有插件都有机会参与处理。
Ceilometer 设计¶
此分析直接影响了我们在实现 ceilometer 时所做的选择。
发现和导入¶
对于查找和加载,我们选择使用入口点,因为它们是最简单的解决方案。所有处理文件而不是导入引用的应用程序都遇到了问题,从实现不佳的导入路径篡改到打包和分发挑战。即使是一些直接处理导入引用的代码也有些棘手。将其留给一个透明地处理不同情况的库,让我们省去了很多麻烦。
它们更容易供用户安装和配置,因为他们不必了解您的代码是如何布局的。这使得它们在代码更改面前更具弹性。
入口点还支持不同的包格式(egg、sdist、操作系统包),因此扩展的分布方式无关紧要。
它们也使 Linux 发行版更容易打包代码,因为包不必共享重叠的安装目录。
入口点类系统有替代实现,但没有一个像 pkg_resources 这样被广泛使用或经过充分测试。
为了进一步简化,我们始终使用入口点,即使对于我们与核心一起分发的插件也是如此。这消除了任何特殊情况。
启用¶
我们想出了一个相当新颖的解决方案来管理哪些插件已启用。对于 Ceilometer,我们希望默认收集数据,但允许部署者禁用某些 [meter] 以节省存储空间,如果他们知道不需要该数据。解决方案是使用显式配置,但将其从正常实现中颠倒过来。
我们假设所有找到的扩展都应该被加载和使用,除非它们在配置文件中被明确禁用。我们在第一个版本中这样做是为了简化配置过程,因为我们假设大多数用户希望使用大多数插件。默认启用意味着用户只需提供要关闭的 [meter] 的简短列表。
Ceilometer 插件在加载时也有机会自动禁用自身。这在轮询插件中特别有用,因为如果收集测量所需资源不可用(例如,它们与不同的虚拟机管理程序或未配置的外部服务一起工作),它们可以告诉应用程序忽略它们。
让插件自行禁用可以避免在插件被要求轮询无法检索的数据时,日志文件中反复出现警告消息。
集成¶
对于我们的集成模式,我们采用了细粒度的 API,使用检查。每个插件类型都有一个单独的命名空间,每个插件实例都指向一个单独的类。应用程序加载并实例化该类,然后调用其方法来确定它提供了什么以及想要什么(订阅哪些通知以及生成哪些 [meter])。
此设计使我们能够避免在每个插件中出现重复的设置或配置代码,因为它们会按需向应用程序提供数据,并且应用程序会自行配置。实例不知道应用程序或彼此。它们仅在应用程序调用它们时运行,从不独立运行。
API 强制执行¶
为了定义每组插件的 API,我们使用 abc 模块创建了一个单独的抽象基类。这为我们提供了一种记录每个插件 API 的方式,并且使用基类的开发人员可以免费获得一些帮助。
由于我们不强制执行类层次结构,因此在调用它们时,我们还会捕获插件的意外错误。
调用¶
我们在不同地方使用了所有三种调用模式。
我们一次只使用一个存储系统,因此我们将存储插件视为驱动程序。
我们加载所有通知插件,然后根据消息内容将传入的消息分派给它们。
我们加载所有轮询插件,并在固定计划上迭代它们。
结论¶
在 ceilometer 中将所有这些都实现完成后,我将部分代码提取到了 stevedore 中。它用一系列管理器类包装了 pkg_resources,这些管理器类实现了加载、启用和调用模式。
