持久性¶
概述¶
为了能够以容错的方式接收原子(或其他引擎进程)的输入并创建输出,需要能够将原子输出的内容放置在某种位置,以便其他原子(或用于其他目的)可以重用它。为了适应这种用法,TaskFlow 提供了一种抽象(由可插拔的 stevedore 后端提供),其概念类似于正在运行的程序内存。
这种抽象服务于以下主要目的
跟踪已完成的操作(内省)。
保存内存,允许从上次保存的状态重新启动,这是重新启动和恢复工作流的关键功能(检查点)。
在运行时将其他元数据与原子关联(无需让这些原子自己保存此数据)。这使得将来可以添加新的元数据,而无需更改原子本身。例如,可以保存以下内容
时序信息(任务运行所需的时间)。
用户信息(任务由谁运行)。
原子/工作流运行的时间(以及原因)。
保存历史数据(失败、成功、中间结果…)以便重试原子能够决定是应该继续还是停止。
你创建的东西…
如何使用¶
在 引擎 构造期间,通常会提供一个后端(它可以是可选的),该后端满足 Backend 抽象。除了提供后端对象之外,还会创建一个 FlowDetail 对象并提供给引擎构造函数(或关联的 load() 辅助函数)(此对象将包含要运行的流程的详细信息)。通常,FlowDetail 对象是从 LogBook 对象创建的(书对象充当 FlowDetail 和 AtomDetail 对象的一种容器)。
准备:一旦引擎开始运行,它将创建一个 Storage 对象,该对象将充当引擎与底层后端存储对象的接口(它提供引擎常用的辅助函数,避免在与提供的 FlowDetail 和 Backend 对象交互时重复代码)。在引擎初始化时,它将提取(或创建)AtomDetail 对象,用于工作流中引擎将要执行的每个原子。
执行: 当引擎开始执行时(有关引擎如何执行此过程的更多详细信息,请参阅 引擎),它将检查任何先前存在的 AtomDetail 对象,以查看是否可以将其用于恢复;有关此主题的更多详细信息,请参阅 恢复。对于尚未完成(或未从之前的运行中正确完成)的原子,只有在任何依赖项输入准备好后才会开始执行。这是通过分析执行图并查看前置 AtomDetail 输出和状态(这些状态可能已在之前的运行中持久化)来完成的。这将导致使用它们以前的信息或运行这些前置原子并将它们的输出保存到 FlowDetail 和 Backend 对象。这种执行、分析和与存储对象的交互将继续(此处描述的是一种简化,实际情况要复杂得多),直到引擎完成运行(此时引擎将成功或失败地尝试运行工作流)。
执行后: 通常,当引擎完成运行时,日志簿将被丢弃(以避免创建无用数据的堆积),并且后端存储将被告知删除给定执行的任何内容。但是,在某些用例中,保留日志簿及其内容可能是有利的。
想到了一些场景
运行时故障分析和分类(保存失败的原因)。
指标(保存与每个原子相关的时间信息,并将其用于离线性能分析,从而可以调整任务和/或隔离和修复缓慢的任务)。
挖掘日志簿以查找趋势(例如,故障)。
保存日志簿以进行进一步的法医分析。
将日志簿导出到 hdfs(或其他 NoSQL 存储)并在其上运行某种类型的 map-reduce 作业。
用法¶
要选择要使用的持久性后端,应使用 fetch() 函数,该函数使用入口点(内部使用 stevedore)来获取和配置你的后端。这比直接访问后端数据类型更简单,并提供了一个通用的函数,可以从中获取后端。
使用此函数获取后端可能如下所示
from taskflow.persistence import backends
...
persistence = backends.fetch(conf={
"connection": "mysql",
"user": ...,
"password": ...,
})
book = make_and_save_logbook(persistence)
...
如上所示,conf 参数充当一个字典,用于获取和配置你的后端。对其的限制如下
一个字典(或类似字典的类型),其中包含键
'connection'的后端类型,以及其他特定于类型的后端参数作为其他键。
类型¶
内存¶
连接:'memory'
将所有数据保留在本地内存中(未持久化到可靠存储)。适用于不需要持久性的场景(以及在单元测试中)。
注意
有关实现细节,请参阅 MemoryBackend。
文件¶
连接:'dir' 或 'file'
将所有数据保留在基于本地磁盘的目录和文件结构中。在系统发生故障的情况下,将在本地持久化(仅允许从同一本地机器恢复)。适用于需要更可靠的持久性以及文件和目录的简单性的情况(每个人都熟悉这种概念)。
注意
有关实现细节,请参阅 DirBackend。
SQLAlchemy¶
连接:'mysql' 或 'postgres' 或 'sqlite'
使用 sqlalchemy 库的模式、连接和数据库交互功能,将所有数据保留在 ACID 兼容数据库中。当你需要比前述解决方案更高的耐久性级别时,很有用。使用这些连接类型时,可以从对等机器恢复引擎(这不适用于使用 sqlite 时)。
模式¶
日志簿
名称 |
类型 |
主键 |
|---|---|---|
created_at |
DATETIME |
False |
updated_at |
DATETIME |
False |
uuid |
VARCHAR |
True |
name |
VARCHAR |
False |
meta |
TEXT |
False |
流程详细信息
名称 |
类型 |
主键 |
|---|---|---|
created_at |
DATETIME |
False |
updated_at |
DATETIME |
False |
uuid |
VARCHAR |
True |
name |
VARCHAR |
False |
meta |
TEXT |
False |
state |
VARCHAR |
False |
parent_uuid |
VARCHAR |
False |
原子详细信息
名称 |
类型 |
主键 |
|---|---|---|
created_at |
DATETIME |
False |
updated_at |
DATETIME |
False |
uuid |
VARCHAR |
True |
name |
VARCHAR |
False |
meta |
TEXT |
False |
atom_type |
VARCHAR |
False |
state |
VARCHAR |
False |
intention |
VARCHAR |
False |
results |
TEXT |
False |
failure |
TEXT |
False |
版本 |
TEXT |
False |
parent_uuid |
VARCHAR |
False |
注意
有关实现细节,请参阅 SQLAlchemyBackend。
Zookeeper¶
连接:'zookeeper'
将所有数据保留在 zookeeper 后端中(zookeeper 暴露文件和目录上的操作,类似于上述 'dir' 或 'file' 连接类型)。在内部,kazoo 库用于与 zookeeper 交互,以对表示为 znodes 的日志簿的内容执行可靠、分布式和原子操作。由于 zookeeper 也是分布式的,因此也可以从对等机器恢复引擎(具有与前面列出的数据库连接类型类似的功能)。
注意
有关实现细节,请参阅 ZkBackend。
接口¶
- taskflow.persistence.backends.fetch(conf, namespace='taskflow.persistence', **kwargs)[source]¶
使用给定的配置获取持久性后端。
此获取方法将在入口点命名空间中查找入口点名称,然后尝试使用提供的配置和任何持久性后端特定 kwargs 来实例化该入口点。
注意(harlowja):为了便于指定配置和后端选项,配置(通常只是一个字典)也可以是一个标识入口点名称和该后端特定配置的 URI 字符串。
例如,给定以下配置 URI
mysql://<not-used>/?a=b&c=d
这将查找名为“mysql”的入口点,并将由 URI 的组件组成的配置对象(在本例中为
{'a': 'b', 'c': 'd'})提供给该持久性后端实例的构造函数。
- taskflow.persistence.backends.backend(conf, namespace='taskflow.persistence', **kwargs)[source]¶
获取后端,连接,升级,然后在完成时关闭它。
这允许获取后端实例,连接到它,升级其模式(如果模式已经是最新版本,则不执行任何操作),然后在上下文管理器语句中使用该后端,并在上下文管理器退出时关闭该后端。
- class taskflow.persistence.base.Connection[source]¶
基类:
object后端连接的基类。
- abstract property backend¶
返回此连接关联的后端。
- abstract update_atom_details(atom_detail)[source]¶
更新给定的原子详情并返回更新后的版本。
注意(harlowja):要更新的详情必须已经通过保存包含给定原子详情的流程详情来创建。
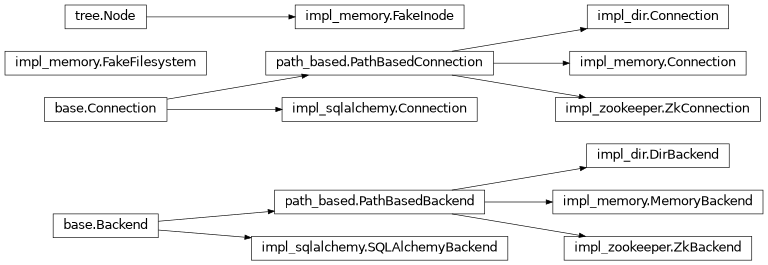
- class taskflow.persistence.path_based.PathBasedBackend(conf)[source]¶
继承自
Backend基于路径解决数据后端持久化数据的后端基类
此后端的子类会将日志簿、流程详情和原子详情写入提供的基路径到某种文件系统类似的存储中。它们将在三个关键目录(一个用于日志簿,一个用于流程详情,一个用于原子详情)中创建和存储这些对象。它们创建这些关联目录,然后在这些目录中创建文件,以表示稍后读取和写入这些对象的内容。
- DEFAULT_PATH = None¶
未提供时使用的默认路径。
- class taskflow.persistence.path_based.PathBasedConnection(backend)[source]¶
继承自
Connection基于路径的后端连接的基类。
- property backend¶
返回此连接关联的后端。
- update_flow_details(flow_detail, ignore_missing=False)[source]¶
更新给定的流程详情并返回更新后的版本。
注意(harlowja):要更新的详情必须已经通过保存包含给定流程详情的日志簿来创建。
模型¶
- class taskflow.persistence.models.LogBook(name, uuid=None)[source]¶
基类:
object流程详情和相关元数据的集合。
通常,此类包含给定引擎(或作业)的流程详情条目的集合,以便这些实体可以跟踪已完成的工作,以便恢复、回滚和各种跟踪目的。
此类包含的数据不必实时持久化到后端存储。此类中的数据仅保证在通过某种后端连接发生保存时才会被持久化。
注意(harlowja):该类的命名类似于船只日志或用于详细记录已完成工作(或未完成工作)的类似类型的记录。
- 变量:
created_at – 创建此日志书时的时间
datetime.datetime对象。updated_at – 上次更新此日志书时的时间
datetime.datetime对象。meta – 与此日志书关联的元数据字典。
- pformat(indent=0, linesep='\n')[source]¶
将此日志书格式化为字符串。
>>> from taskflow.persistence import models >>> tmp = models.LogBook("example") >>> print(tmp.pformat()) LogBook: 'example' - uuid = ... - created_at = ...
- add(fd)[source]¶
将新的流程详情添加到此日志书。
注意(harlowja):如果已存在具有相同 uuid 的流程详情,则现有流程详情将被新提供的流程详情覆盖。
不保证这些详情会立即保存。
- find(flow_uuid)[source]¶
找到与给定 uuid 对应的流程详情。
- 返回值:
具有该 uuid 的流程详情
- 返回类型:
FlowDetail(如果未找到,则为None)
- merge(lb, deep_copy=False)[source]¶
将当前对象的状态与给定对象的状态合并。
如果提供
deep_copy为真值,则本地对象将使用copy.deepcopy将此对象的本地属性替换为提供的属性(仅当此对象的属性与提供的属性之间存在差异时)。如果deep_copy为假值(默认值),则在检测到差异时将发生引用复制。注意(harlowja):如果提供的对象是此对象本身,则不进行任何合并。另外请注意,这不会合并两个对象中包含的流程详情。
- 返回值:
此日志书(与传入对象合并后)
- 返回类型:
- to_dict(marshal_time=False)[source]¶
将此对象的内部状态转换为
dict。注意(harlowja):返回的
dict不包含任何包含的流程详情。- 返回值:
此日志书以
dict形式
- classmethod from_dict(data, unmarshal_time=False)[source]¶
将给定的
dict转换为此类的实例。注意(harlowja):提供的
dict应该来自先前对to_dict()的调用。- 返回值:
一个新的日志书
- 返回类型:
- property uuid¶
此日志书的唯一标识符。
- property name¶
此日志书的名称。
- class taskflow.persistence.models.FlowDetail(name, uuid)[source]¶
基类:
object原子详情和相关元数据的集合。
通常,此类包含表示给定流程结构中原子的原子详情条目的集合(以及与该流程相关的任何其他所需元数据)。
此类包含的数据不必实时持久化到后端存储。此类中的数据仅保证在通过某种后端连接发生保存(或更新)时才会被持久化。
- 变量:
meta – 与此流程详情关联的元数据字典。
- state¶
与此流程详情关联的流程的状态。
- update(fd)[source]¶
将对象的状态更新为与给定对象的状态相同。
这将直接将给定流程详情的私有和公共属性分配给此对象(替换此对象中的任何现有属性;即使它们是相同的)。
注意(harlowja):如果提供的对象是此对象本身,则不进行任何更新。
- 返回值:
此流程详情
- 返回类型:
- pformat(indent=0, linesep='\n')[source]¶
将此流程详情格式化为字符串。
>>> from oslo_utils import uuidutils >>> from taskflow.persistence import models >>> flow_detail = models.FlowDetail("example", ... uuid=uuidutils.generate_uuid()) >>> print(flow_detail.pformat()) FlowDetail: 'example' - uuid = ... - state = ...
- merge(fd, deep_copy=False)[source]¶
将当前对象的状态与给定对象的状态合并。
如果提供
deep_copy为真值,则本地对象将使用copy.deepcopy将此对象的本地属性替换为提供的属性(仅当此对象的属性与提供的属性之间存在差异时)。如果deep_copy为假值(默认值),则在检测到差异时将发生引用复制。注意(harlowja):如果提供的对象是此对象本身,则不进行任何合并。另外,这不会合并两个对象中包含的原子详情。
- 返回值:
此流程详情(与传入对象合并后)
- 返回类型:
- copy(retain_contents=True)[source]¶
复制此流程详情。
创建此流程详情的浅拷贝。如果此详情包含流程详情,并且
retain_contents为真值(默认值),则原子详情容器将被浅拷贝(其中包含的原子详情将不会被拷贝)。如果retain_contents为假值,则复制的流程详情将不包含任何包含的原子详情(但它将复制本地对象的其余属性)。- 返回值:
一个新的流程详情
- 返回类型:
- classmethod from_dict(data)[source]¶
将给定的
dict转换为此类的实例。注意(harlowja):提供的
dict应该来自先前对to_dict()的调用。- 返回值:
一个新的流程详情
- 返回类型:
- add(ad)[source]¶
将新的原子详情添加到此流程详情。
注意(harlowja):如果已存在具有相同 uuid 的原子详情,则现有原子详情将被新提供的原子详情覆盖。
不保证这些详情会立即保存。
- find(ad_uuid)[source]¶
找到与给定 uuid 对应的原子详情。
- 返回值:
具有该 uuid 的原子详情
- 返回类型:
AtomDetail(如果未找到,则为None)
- property uuid¶
此流程详情的唯一标识符。
- property name¶
此流程详情的名称。
- class taskflow.persistence.models.AtomDetail(name, uuid)[source]¶
基类:
object包含原子特定运行时信息和元数据。
这是一个基础抽象类,包含用于在原子运行之前、期间或之后将其连接到持久化层的属性。它包括原子可能产生的任何结果、原子可能处于的任何状态(例如
FAILURE)、运行过程中发生的任何异常以及可能在抛出异常期间发生的任何关联堆栈跟踪。它还可能包含应与连接的原子详细信息一起存储的任何其他元数据。此类包含的数据不必实时持久化到后端存储。此类中的数据仅保证在通过某种后端连接发生保存(或更新)时才会被持久化。
- 变量:
intention – 与此原子详细信息关联的原子执行策略(由引擎/其他用于确定是否需要执行、撤销、重试关联的原子等)。
meta – 与此原子详细信息关联的元数据字典。
version – 表示此原子详细信息关联的原子版本的版本元组或字符串(通常用于内省和任何数据迁移策略)。
results – 原子从其
execute方法或其他来源产生的任何结果。revert_results – 原子从其
revert方法或其他来源产生的任何结果。AtomDetail.failure – 如果原子失败(由于其
execute方法引发异常),这将是一个Failure对象,表示该失败(如果没有失败,则设置为 None)。revert_failure – 如果原子失败(可能由于其
revert方法引发异常),这将是一个Failure对象,表示该失败(如果没有失败,则设置为 None)。
- state¶
与此原子详细信息关联的原子状态。
- property last_results¶
获取原子的最后结果。
如果原子产生了许多结果(例如,如果它已被重试、撤销、执行等),这将返回许多结果中的最后一个。
- update(ad)[source]¶
将对象的状态更新为与给定对象相同。
这将直接将给定原子详细信息的私有和公共属性分配给此对象(替换此对象中的任何现有属性;即使它们是相同的)。
注意(harlowja):如果提供的对象是此对象本身,则不进行任何更新。
- 返回值:
此原子详细信息
- 返回类型:
- abstract merge(other, deep_copy=False)[source]¶
将当前对象的状态与给定对象的状态合并。
如果提供
deep_copy为真值,则本地对象将使用copy.deepcopy将此对象的本地属性替换为提供的属性(仅当此对象的属性与提供的属性之间存在差异时)。如果deep_copy为假值(默认值),则在检测到差异时将发生引用复制。注意(harlowja):如果提供的对象是此对象本身,则不执行任何合并。请注意,此方法不合并任何结果。该操作必须由子类实现并覆盖此抽象方法,并根据需要提供自己的合并。
- 返回值:
此原子详细信息(与传入对象合并后)
- 返回类型:
- classmethod from_dict(data)[source]¶
将给定的
dict转换为此类的实例。注意(harlowja):提供的
dict应该来自先前对to_dict()的调用。- 返回值:
一个新的原子详细信息
- 返回类型:
- property uuid¶
此原子详细信息的唯一标识符。
- property name¶
此原子详细信息的名称。
- class taskflow.persistence.models.TaskDetail(name, uuid)[source]¶
Bases:
AtomDetail任务详细信息(原子详细信息通常与
Task原子关联)。- reset(state)[source]¶
重置此任务详细信息并设置
state属性值。这将将任何先前设置的
results、failure和revert_results属性重置为None,并将状态设置为提供的值,以及将此任务详细信息的intention属性设置为EXECUTE。
- merge(other, deep_copy=False)[source]¶
合并当前任务详细信息与给定的详细信息。
注意(harlowja):此合并不会复制和替换
results或revert_results(如果不同)。相反,当前对象的results和revert_results属性直接成为(通过赋值)其他对象的属性。另请注意,如果提供的对象是此对象本身,则不执行任何合并。参见:https://bugs.launchpad.net/taskflow/+bug/1452978,了解如果以更深层次复制此对象会发生什么(例如,使用
copy.deepcopy或使用copy.copy)。- 返回值:
此任务详细信息(与传入对象合并后)
- 返回类型:
- copy()[source]¶
复制此任务详细信息。
创建此任务详细信息的浅拷贝(此对象维护的任何元数据和版本信息都通过
copy.copy进行浅拷贝)。注意(harlowja):如果
results或revert_results属性不同,则此副本不会复制和替换它们。相反,当前对象的results和revert_results属性直接成为(通过赋值)克隆对象的属性。参见:https://bugs.launchpad.net/taskflow/+bug/1452978,了解如果以更深层次复制此对象会发生什么(例如,使用
copy.deepcopy或使用copy.copy)。- 返回值:
一个新的任务详细信息
- 返回类型:
- class taskflow.persistence.models.RetryDetail(name, uuid)[source]¶
Bases:
AtomDetail重试详细信息(原子详细信息通常与
Retry原子关联)。- reset(state)[source]¶
重置此重试详细信息并设置
state属性值。这将将任何先前添加的
results重置为空列表,并将failure和revert_failure和revert_results属性重置为None,并将状态设置为提供的值,以及将此重试详细信息的intention属性设置为EXECUTE。
- copy()[source]¶
复制此重试详细信息。
创建此重试详情的浅拷贝(任何元数据和版本信息都会通过
copy.copy进行浅拷贝)。注意(harlowja):此拷贝不会拷贝传入对象
results或revert_results属性。相反,此对象的results属性列表会被迭代,并构造一个新的列表,其中该列表中每个(data, failures)元素都会将其failures(每个命名Failure对象的字典,该对象发生错误)拷贝,但其data则保持不变。完成此操作后,该新列表将成为(通过赋值)克隆对象的results属性。revert_results将直接赋值给克隆对象的revert_results属性。请参阅:https://bugs.launchpad.net/taskflow/+bug/1452978,了解如果
results中的data在更深层次被拷贝(例如,通过使用copy.deepcopy或使用copy.copy)会发生什么情况。- 返回值:
一个新的重试详情
- 返回类型:
- property last_results¶
最后产生的结果。
- property last_failures¶
最后产生的失败字典。
注意(harlowja):这与本地
failure属性不同,因为在results属性中获得的失败字典(即此返回值)来自关联的原子失败(这与关联到此原子详情的重试单元的直接相关失败不同)。
- merge(other, deep_copy=False)[source]¶
合并当前的重试详情和给定的重试详情。
注意(harlowja):此合并不会深度拷贝传入对象的
results属性(如果不同)。相反,传入对象的results属性列表始终会被迭代,并构造一个新的列表,其中该列表中每个(data, failures)元素都会将其failures(每个命名Failure对象发生的字典)拷贝,但其data则保持不变。完成此操作后,该新列表将成为(通过赋值)此对象的results属性。另外请注意,如果提供的对象是此对象本身,则不会进行任何合并。请参阅:https://bugs.launchpad.net/taskflow/+bug/1452978,了解如果
results中的data在更深层次被拷贝(例如,通过使用copy.deepcopy或使用copy.copy)会发生什么情况。- 返回值:
此重试详情(与传入对象合并后)
- 返回类型:
实现¶
内存¶
- class taskflow.persistence.backends.impl_memory.FakeInode(item, path, value=None)[source]¶
基类:
Node一个内存中的文件系统inode类对象。
- class taskflow.persistence.backends.impl_memory.FakeFilesystem(deep_copy=True)[source]¶
基类:
object一个内存中的文件系统类结构。
此文件系统仅使用POSIX风格的路径,因此用户必须小心使用
posixpath模块,而不是os.path模块,后者会根据运行Python的操作系统而变化(选择使用posixpath的决定是为了避免与内存模拟文件系统无关的路径变化)。不是线程安全的,当单个文件系统同时被多个线程修改时。例如,多个线程同时调用
clear()可能会导致问题。当仅发生get()或其他只读操作(例如调用ls())时,它是线程安全的。示例用法
>>> from taskflow.persistence.backends import impl_memory >>> fs = impl_memory.FakeFilesystem() >>> fs.ensure_path('/a/b/c') >>> fs['/a/b/c'] = 'd' >>> print(fs['/a/b/c']) d >>> del fs['/a/b/c'] >>> fs.ls("/a/b") [] >>> fs.get("/a/b/c", 'blob') 'blob'
- root_path = '/'¶
内存文件系统的根路径。
- static split(p)¶
将路径名拆分为一个
(head, tail)元组。
- class taskflow.persistence.backends.impl_memory.MemoryBackend(conf=None)[source]¶
基础类:
PathBasedBackend一个内存后端(非持久化)。
此后端将日志本、流程详情和原子详情写入内存文件系统类似的结构(根目录由
memory实例变量指定)。此后端不提供真正的事务语义。它保证使用读/写锁,在写入和读取时不会出现线程间的竞争条件。
- DEFAULT_PATH = '/'¶
未提供时使用的默认路径。
文件¶
- class taskflow.persistence.backends.impl_dir.DirBackend(conf)[source]¶
基础类:
PathBasedBackend基于目录和文件的后端。
此后端不提供真正的事务语义。它保证使用一致的文件锁层次结构,在写入和读取时不会出现进程间的竞争条件。
示例配置
conf = { "path": "/tmp/taskflow", # save data to this root directory "max_cache_size": 1024, # keep up-to 1024 entries in memory }
- DEFAULT_FILE_ENCODING = 'utf-8'¶
将文件从文本/Unicode编码为二进制或从二进制编码为文本/Unicode时使用的默认编码。
SQLAlchemy¶
- class taskflow.persistence.backends.impl_sqlalchemy.SQLAlchemyBackend(conf, engine=None)[source]¶
继承自
Backend一个 SQLAlchemy 后端。
示例配置
conf = { "connection": "sqlite:////tmp/test.db", }
- class taskflow.persistence.backends.impl_sqlalchemy.Connection(backend, upgrade_lock)[source]¶
继承自
Connection- property backend¶
返回此连接关联的后端。
- update_atom_details(atom_detail)[source]¶
更新给定的原子详情并返回更新后的版本。
注意(harlowja):要更新的详情必须已经通过保存包含给定原子详情的流程详情来创建。
Zookeeper¶
- class taskflow.persistence.backends.impl_zookeeper.ZkBackend(conf, client=None)[source]¶
基础类:
PathBasedBackend一个基于 Zookeeper 的后端。
示例配置
conf = { "hosts": "192.168.0.1:2181,192.168.0.2:2181,192.168.0.3:2181", "path": "/taskflow", }
请注意,kazoo 客户端的创建是通过
make_client()实现的,并且此后端配置的传递到该函数以创建客户端可能发生在__init__时。这意味着此后端配置中的某些参数可能会提供给make_client(),因此,如果调用者未提供客户端,则将根据make_client()的规范创建一个客户端。- DEFAULT_PATH = '/taskflow'¶
未提供时使用的默认路径。
Storage¶
- class taskflow.storage.Storage(flow_detail, backend=None, scope_fetcher=None)[source]¶
基类:
object引擎和日志簿及其后端(如果有)之间的接口。
此类提供了一个简单的接口,用于保存给定流程的原子以及相关的活动和结果到持久化层(日志簿、原子详情、流程详情),供引擎使用。通过此接口与底层存储和后端机制交互,而不是直接访问这些对象,这样更方便。
注意(harlowja):如果未提供后端,则将自动使用内存后端,并且提供的流程详情对象将在该对象的整个生命周期内放入其中。
- injector_name = '_TaskFlow_INJECTOR'¶
注入器任务详情名称。
此任务详情是一个特殊的详情,它将自动创建并保存,用于存储持久化注入的值(与它冲突的名称必须避免),这些值对正在执行的流程是全局的。
- property lock¶
用于确保多线程安全的读写锁。
这不保护相同的存储对象被多个引擎/用户在多个进程(或不同机器)中使用(某些后端处理这种情况比其他后端更好(例如,通过使用序列标识符),并且使这种情况更好是一个持续进行中的工作)。
- property flow_name¶
此存储单元关联的流程详情名称。
- property flow_uuid¶
此存储单元关联的流程详情 UUID。
- property flow_meta¶
此存储单元关联的流程详情元数据。
- property backend¶
此存储单元关联的后端。
- update_atom_metadata(atom_name, update_with)[source]¶
更新原子关联的元数据。
此更新将采用提供的字典或 (键,值) 对列表,以包含在更新的元数据中(较新的键将覆盖旧的键),并在合并后将更新的数据保存到基础持久化层。
- set_task_progress(task_name, progress, details=None)[source]¶
设置任务的进度。
- 参数:
task_name – 任务名称
progress – 任务进度 (0.0 <-> 1.0)
details – 任何任务特定的进度详情
- get_task_progress_details(task_name)[source]¶
根据任务名称获取任务的进度详情。
- 参数:
task_name – 任务名称
- 返回值:
如果未定义 progress_details,则为 None,否则为 progress_details 字典
- get(atom_name)¶
从存储中获取原子的
execute结果。
- get_failures()¶
获取此流程发生的所有
execute失败。
- inject_atom_args(atom_name, pairs, transient=True)[source]¶
仅为特定原子添加值到存储中。
- 参数:
transient – 以内存中方式保存数据,而不是将其持久化到后端存储(适用于资源类对象或类似无法持久化的对象)
此方法注入字典/参数对,用于原子,以便在计划执行该原子时,它将立即访问这些参数。
注意
注入的原子参数优先于前置原子提供的参数或注入到流程作用域中的参数(使用
inject()方法)。警告
应该注意的是,注入的原子参数(作用域限定于具有给定名称的原子)应该尽可能是可序列化的。这是 基于 worker 的引擎 的一个要求,它必须序列化(通常使用
json)所有原子的execute()和revert()参数,以便能够将这些参数传输到目标 worker(s)。如果应用/期望的用例是以后使用基于 worker 的引擎,那么强烈建议确保所有注入的原子(即使是瞬态的原子)都是可序列化的,以避免以后可能出现的问题(当一个对象实际上不可序列化时)。
- inject(pairs, transient=False)[source]¶
将值添加到存储中。
应该使用此方法将流程参数(流程中任何原子未满足的要求)放入存储中。
- 参数:
transient – 以内存中方式保存数据,而不是将其持久化到后端存储(适用于资源类对象或类似无法持久化的对象)
警告
应该注意的是,注入的流程参数(作用域限定于此流程中的所有原子)应该尽可能是可序列化的。这是 基于 worker 的引擎 的一个要求,它必须序列化(通常使用
json)所有原子的execute()和revert()参数,以便能够将这些参数传输到目标 worker(s)。如果应用/期望的用例是以后使用基于 worker 的引擎,那么强烈建议确保所有注入的原子(即使是瞬态的原子)都是可序列化的,以避免以后可能出现的问题(当一个对象实际上不可序列化时)。
- fetch_unsatisfied_args(atom_name, args_mapping, scope_walker=None, optional_args=None)[source]¶
使用原子的参数映射获取未满足的
execute参数。注意(harlowja):这会考虑到提供的作用域 walker 原子,它们应该在运行时生成所需的值,以及瞬态/持久的流程和原子特定的注入参数。它不检查提供者是否实际生成了所需的值;它只是检查它们是否已注册以在将来生成它。
- fetch_mapped_args(args_mapping, atom_name=None, scope_walker=None, optional_args=None)[source]¶
使用其参数映射获取原子的
execute参数。
- change_flow_state(state)[source]¶
将流程从旧状态转换为新状态。
如果转换执行成功,则返回
(True, old_state),如果被忽略,则返回(False, old_state),如果转换无效,则引发InvalidState异常。
层级¶