Compute 调度器¶
Compute 使用 nova-scheduler 服务来确定如何分派计算请求。例如,nova-scheduler 服务确定虚拟机应该在哪个主机或节点上启动。你可以通过各种选项配置调度器。
在默认配置中,此调度器会考虑满足以下所有条件的主机
位于请求的 可用区 (
map_az_to_placement_aggregate) 放置预过滤。能够服务于请求,这意味着处理目标节点的 nova-compute 服务可用且未禁用 (
ComputeFilter)。满足与实例类型关联的额外规格 (
ComputeCapabilitiesFilter)。满足实例镜像属性上指定的任何架构、hypervisor 类型或虚拟机模式属性 (
ImagePropertiesFilter)。位于与其他组的实例不同的主机上(如果请求的话)(
ServerGroupAntiAffinityFilter)。位于一组组主机中(如果请求的话)(
ServerGroupAffinityFilter)。
当实例被迁移、调整大小、撤离或在被搁置后恢复时,调度器会选择一个新的主机。
在从主机撤离实例时,调度器服务会遵守管理员在 nova evacuate 命令中定义的的目标主机。如果管理员未定义目标,则调度器确定目标主机。有关实例撤离的信息,请参阅 撤离实例。
预过滤器¶
从 Rocky 版本开始,调度过程包括一个预过滤步骤,以提高后续阶段的效率。这些预过滤器在很大程度上是可选的,用于增强发送到 placement 的请求,以减少基于 placement 能够为我们回答的属性的候选计算主机集合。除了此处列出的预过滤器之外,还请参阅 使用 Placement 的租户隔离 和 使用 Placement 的可用区。
Compute 镜像类型支持¶
20.0.0 版本新增:(Train)
从 Train 版本开始,提供了一个预过滤器,用于排除不支持用于启动请求的镜像的 disk_format 的计算节点。通过将 scheduler.query_placement_for_image_type_support 设置为 True 来启用此行为。例如,当使用 ceph 作为临时后端时,libvirt 驱动程序不支持 qcow2 镜像(没有昂贵的转换步骤)。在这种情况下(尤其是在你拥有混合的 ceph 和非 ceph 支持的计算时),启用此功能将确保调度器不会将请求发送到将 qcow2 镜像启动到由 ceph 支持的计算。
Compute 禁用状态支持¶
20.0.0 版本新增:(Train)
从 Train 版本开始,有一个强制性的 预过滤器,它将排除禁用的计算节点,类似于(但不完全替换)ComputeFilter。具有 COMPUTE_STATUS_DISABLED 特性的计算节点资源提供程序将被排除为调度候选者。该特性由 nova-compute 服务管理,应镜像 os-services API 中相关计算服务记录上的 disabled 状态。例如,如果计算服务的状态为 disabled,则该服务的相关计算节点资源提供程序应具有 COMPUTE_STATUS_DISABLED 特性。当服务状态为 enabled 时,应删除 COMPUTE_STATUS_DISABLED 特性。
如果计算服务在状态更改时关闭,则该特性将在服务重新启动时同步。同样,如果在尝试向给定资源提供程序添加或删除特性时发生错误,则该特性将在 update_available_resource 定期任务运行时同步 - 该任务由 update_resources_interval 配置选项控制。
隔离聚合¶
20.0.0 版本新增:(Train)
从 Train 版本开始,提供了一个可选的 placement 预请求过滤器 通过隔离聚合过滤主机。启用后,服务器的 flavor 和镜像中所需的特性必须至少是聚合的 metadata 中所需的特性,才能使服务器有资格在聚合中的主机上启动。
Filter 调度器¶
23.0.0 版本变更: (Wallaby)
删除了对自定义调度器驱动程序的支持。现在仅支持 filter 调度器。
Nova 的调度器,称为filter 调度器,支持过滤和加权,以便就应该在何处创建新实例做出明智的决策。
当调度器收到资源请求时,它首先应用过滤器来确定哪些主机有资格在分派资源时进行考虑。过滤器是二进制的:主机要么被过滤器接受,要么被拒绝。被过滤器接受的主机然后由不同的算法处理,以决定使用哪些主机来满足该请求,如 权重 部分所述。
过滤
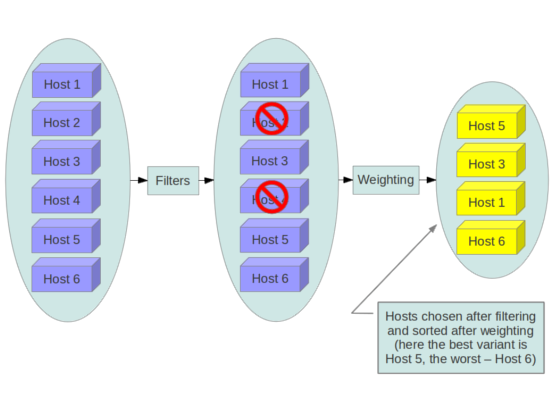
从 Rocky 版本开始,调度过程包括一个预过滤步骤,以提高后续阶段的效率。 filter_scheduler.available_filters 配置选项为 Compute 服务提供调度器可用的过滤器列表。默认设置指定包含在 Compute 服务中的所有过滤器。此配置选项可以多次指定。例如,如果你在 Python 中实现了自己的自定义过滤器,名为 myfilter.MyFilter,并且你想使用内置过滤器和你的自定义过滤器,你的 nova.conf 文件将包含
[filter_scheduler]
available_filters = nova.scheduler.filters.all_filters
available_filters = myfilter.MyFilter
filter_scheduler.enabled_filters 配置选项在 nova.conf 中定义了 nova-scheduler 服务应用的过滤器列表。
过滤器¶
以下部分描述了可用的计算过滤器。
使用以下配置选项配置过滤器
filter_scheduler.available_filters- 定义向调度器提供的过滤器类。此设置可以使用多次。filter_scheduler.enabled_filters- 在可用过滤器中,定义了调度器默认使用的过滤器。
每个过滤器以不同的方式选择主机并具有不同的成本。filter_scheduler.enabled_filters 的顺序会影响调度性能。一般建议尽快过滤掉无效的主机,以避免不必要的成本。我们可以按成本降序对 filter_scheduler.enabled_filters 项目进行排序。例如,ComputeFilter 优于任何资源计算过滤器,如 NUMATopologyFilter。
AggregateImagePropertiesIsolation¶
已更改于版本 12.0.0:(Liberty)
在 12.0.0 Liberty 之前,可以使用任意 metadata 指定和使用。从 Liberty 开始,nova 仅解析 标准 metadata。如果你想使用任意 metadata,请考虑使用 AggregateInstanceExtraSpecsFilter 过滤器。
匹配镜像的 metadata 中定义的属性与聚合的属性,以确定主机匹配
如果主机属于聚合,并且聚合定义了一个或多个与镜像的属性匹配的 metadata,则该主机是启动镜像实例的候选主机。
如果主机不属于任何聚合,则它可以从所有镜像启动实例。
例如,以下聚合 myWinAgg 具有 Windows 操作系统作为 metadata(命名为“windows”)
$ openstack aggregate show myWinAgg
+-------------------+----------------------------+
| Field | Value |
+-------------------+----------------------------+
| availability_zone | zone1 |
| created_at | 2017-01-01T15:36:44.000000 |
| deleted | False |
| deleted_at | None |
| hosts | ['sf-devel'] |
| id | 1 |
| name | myWinAgg |
| properties | os_distro='windows' |
| updated_at | None |
+-------------------+----------------------------+
在此示例中,因为以下 Win-2012 镜像具有 windows 属性,所以它在 sf-devel 主机上启动(所有其他过滤器相同)
$ openstack image show Win-2012
+------------------+------------------------------------------------------+
| Field | Value |
+------------------+------------------------------------------------------+
| checksum | ee1eca47dc88f4879d8a229cc70a07c6 |
| container_format | bare |
| created_at | 2016-12-13T09:30:30Z |
| disk_format | qcow2 |
| ... |
| name | Win-2012 |
| ... |
| properties | os_distro='windows' |
| ... |
你可以通过在 nova.conf 文件中使用以下选项来配置 AggregateImagePropertiesIsolation 过滤器
filter_scheduler.aggregate_image_properties_isolation_namespacefilter_scheduler.aggregate_image_properties_isolation_separator
注意
此过滤器具有如 bug 1677217 中所述的限制,这些限制在 placement 通过隔离聚合过滤主机 请求过滤器中得到解决。
有关更多信息,请参阅 主机聚合。
AggregateInstanceExtraSpecsFilter¶
匹配实例类型额外规格中定义的属性与管理员在主机聚合上定义的属性。适用于范围为 aggregate_instance_extra_specs 的规格。可以给出多个值,以逗号分隔列表的形式。为了保持向后兼容性,也适用于非范围规格;强烈不建议这样做,因为它在启用这两个过滤器时与 ComputeCapabilitiesFilter 过滤器冲突。
有关更多信息,请参阅 主机聚合。
AggregateIoOpsFilter¶
通过每个聚合的 max_io_ops_per_host 值过滤主机磁盘分配。如果未找到聚合值,则值将回退到由 filter_scheduler.max_io_ops_per_host 配置选项定义的全局设置。如果主机位于多个聚合中并且找到多个值,则将使用最小值。
有关更多信息,请参阅 主机聚合 和 IoOpsFilter。
AggregateMultiTenancyIsolation¶
确保租户隔离的主机聚合中的主机仅对指定的一组租户可用。如果主机位于具有 filter_tenant_id 元数据键的聚合中,则该主机只能从该租户或逗号分隔的租户列表中构建实例。主机可以位于不同的聚合中。如果主机不属于具有元数据键的聚合,则该主机可以从所有租户构建实例。这不会限制租户在租户隔离聚合之外的主机上创建服务器。
例如,考虑有两个可用于调度的可用主机,HostA 和 HostB。 HostB 位于隔离到租户 X 的聚合中。来自租户 X 的服务器创建请求将在调度期间将 HostA 或 HostB 作为候选主机。来自另一个租户 Y 的服务器创建请求将导致只有 HostA 作为调度候选主机,因为 HostA 不属于租户隔离聚合。
AggregateNumInstancesFilter¶
按聚合中实例的数量过滤主机,每个聚合具有 max_instances_per_host 值。如果未找到聚合值,则该值将回退到由 filter_scheduler.max_instances_per_host 配置选项定义的全局设置。如果主机位于多个聚合中,因此找到多个值,则将使用最小值。
请参阅 主机聚合 和 NumInstancesFilter 以获取更多信息。
AggregateTypeAffinityFilter¶
如果实例的风味名称与聚合的元数据中设置的 instance_type 键匹配,或者如果未设置 instance_type 键,则过滤聚合中的主机。
instance_type 元数据条目的值是一个字符串,可以包含单个 instance_type 名称或逗号分隔的 instance_type 名称列表,例如 m1.nano 或 m1.nano,m1.small。
注意
实例类型是风味的旧称。
有关更多信息,请参阅 主机聚合。
AllHostsFilter¶
这是一个无操作过滤器。它不会消除任何可用主机。
ComputeCapabilitiesFilter¶
通过匹配风味附加规格中定义的属性与计算能力来过滤主机。如果附加规格键包含冒号 (:),则冒号之前的一切被视为命名空间,冒号之后的一切被视为要匹配的键。如果存在命名空间且不是 capabilities,则过滤器将忽略该命名空间。例如 capabilities:cpu_info:features 是一个有效的范围格式。为了向后兼容,如果不存在命名空间,过滤器还将附加规格键视为要匹配的键;强烈不建议这样做,因为它与同时启用这两个过滤器时的 AggregateInstanceExtraSpecsFilter 过滤器冲突。
附加规格可以在键/值对的值字符串的开头有一个运算符。如果没有指定运算符,则默认运算符为 s==。有效的运算符是
=(作为数字等于或大于;与 vcpus 情况相同)==(作为数字等于)!=(作为数字不等于)>=(作为数字大于或等于)<=(作为数字小于或等于)s==(作为字符串等于)s!=(作为字符串不等于)s>=(作为字符串大于或等于)s>(作为字符串大于)s<=(作为字符串小于或等于)s<(作为字符串小于)<in>(子字符串)<all-in>(集合中包含所有元素)<or>(找到其中一个)
示例是:>= 5、s== 2.1.0、<in> gcc、<all-in> aes mmx 和 <or> fpu <or> gpu
可以使用的有用键及其值的一些属性包含
free_ram_mb(与数字进行比较,值如>= 4096)free_disk_mb(与数字进行比较,值如>= 10240)host(与字符串进行比较,值如<in> compute、s== compute_01)hypervisor_type(与字符串进行比较,值如s== QEMU、s== ironic)hypervisor_version(与数字进行比较,值如>= 1005003、== 2000000)num_instances(与数字进行比较,值如<= 10)num_io_ops(与数字进行比较,值如<= 5)vcpus_total(与数字进行比较,值如= 48、>=24)vcpus_used(与数字进行比较,值如= 0、<= 10)
一些虚拟驱动程序支持将 CPU 特性报告给 Placement 服务。如果该功能可用,您应该考虑在风味中使用特性而不是 ComputeCapabilitiesFilter,因为特性为某些虚拟驱动程序中的 CPU 功能提供了一致的命名,并且查询特性是高效的。有关详细信息,请参阅 功能支持矩阵、必需的特性、禁止的特性 和 将 CPU 特性报告给 Placement 服务。
另请参阅 计算能力作为特性。
ComputeFilter¶
通过所有处于运行和启用状态的主机。
通常,您应该始终启用此过滤器。
DifferentHostFilter¶
将实例调度到与一组实例不同的主机上。要利用此过滤器,请求者必须传递一个调度器提示,使用 different_host 作为键,并使用实例 UUID 列表作为值。此过滤器与 SameHostFilter 相反。
例如,在使用 openstack server create 命令时,使用 --hint 标志
$ openstack server create \
--image cedef40a-ed67-4d10-800e-17455edce175 --flavor 1 \
--hint different_host=a0cf03a5-d921-4877-bb5c-86d26cf818e1 \
--hint different_host=8c19174f-4220-44f0-824a-cd1eeef10287 \
server-1
使用 API 时,使用 os:scheduler_hints 键。例如
{
"server": {
"name": "server-1",
"imageRef": "cedef40a-ed67-4d10-800e-17455edce175",
"flavorRef": "1"
},
"os:scheduler_hints": {
"different_host": [
"a0cf03a5-d921-4877-bb5c-86d26cf818e1",
"8c19174f-4220-44f0-824a-cd1eeef10287"
]
}
}
ImagePropertiesFilter¶
基于实例镜像中定义的属性过滤主机。它通过主机是否可以支持实例中包含的指定镜像属性来传递主机。属性包括架构、hypervisor 类型、hypervisor 版本和虚拟机模式。
例如,一个实例可能需要运行基于 ARM 处理器的主机,以及 QEMU 作为 hypervisor。您可以使用以下方式装饰镜像
$ openstack image set --architecture arm --property img_hv_type=qemu \
img-uuid
过滤器检查的镜像属性是
hw_architecture描述镜像所需的机器架构。示例包括
i686、x86_64、arm和ppc64。已更改于版本 12.0.0:(Liberty)
此属性以前称为
architecture。img_hv_type描述镜像所需的 hypervisor。示例包括
qemu。注意
qemu用于 QEMU 和 KVM hypervisor 类型。已更改于版本 12.0.0:(Liberty)
此属性以前称为
hypervisor_type。img_hv_requested_version描述镜像所需的 hypervisor 版本。该属性仅支持 HyperV hypervisor 类型。它可以用于启用对多个 hypervisor 版本的支持,并防止带有较新 HyperV 工具的实例被配置到较旧版本的 hypervisor 上。如果可用,则将属性值与计算主机的 hypervisor 版本进行比较。
要按 hypervisor 版本过滤主机,请将
img_hv_requested_version属性添加到镜像的元数据中,并传递一个运算符和一个所需的 hypervisor 版本作为其值$ openstack image set --property hypervisor_type=qemu --property \ hypervisor_version_requires=">=6000" img-uuid
已更改于版本 12.0.0:(Liberty)
此属性以前称为
hypervisor_version_requires。hw_vm_mode描述镜像所需的 hypervisor 应用程序二进制接口 (ABI)。示例包括
xen用于 Xen 3.0 准虚拟 ABI、hvm用于本机 ABI 和exe用于容器 virt 可执行 ABI。已更改于版本 12.0.0:(Liberty)
此属性以前称为
vm_mode。
IsolatedHostsFilter¶
允许管理员定义一组特殊的(隔离的)镜像和一组特殊的(隔离的)主机,使得隔离的镜像只能在隔离的主机上运行,而隔离的主机只能运行隔离的镜像。可以使用标志 restrict_isolated_hosts_to_isolated_images 来强制隔离的主机仅运行隔离的镜像。
过滤器内的逻辑取决于配置选项 restrict_isolated_hosts_to_isolated_images,默认值为 True。当为 True 时,基于卷的实例将不会放置在隔离的主机上。当为 False 时,基于卷的实例可以放置在任何主机上,无论是隔离的还是非隔离的。
管理员必须使用 filter_scheduler.isolated_hosts 和 filter_scheduler.isolated_images 配置选项来指定隔离的镜像和主机集。例如
[filter_scheduler]
isolated_hosts = server1, server2
isolated_images = 342b492c-128f-4a42-8d3a-c5088cf27d13, ebd267a6-ca86-4d6c-9a0e-bd132d6b7d09
您还可以使用配置选项 filter_scheduler.restrict_isolated_hosts_to_isolated_images 指定隔离的主机仅用于特定的隔离镜像。
IoOpsFilter¶
根据主机上的并发 I/O 操作对其进行过滤。并发 I/O 操作过多的主机将被过滤掉。 filter_scheduler.max_io_ops_per_host 选项指定允许在主机上运行的最大 I/O 密集型实例数量。如果主机上运行的处于构建、调整大小、快照、迁移、救援或取消保护任务状态中的实例数量超过 filter_scheduler.max_io_ops_per_host,则调度器将忽略该主机。
JsonFilter¶
警告
此过滤器默认未启用,且未经过全面测试,因此可能无法按预期方式工作。此外,过滤器变量基于 HostState 类的属性,这些属性可能会随着版本的发布而变化,因此通常不建议使用此过滤器。请考虑使用其他过滤器,例如 ImagePropertiesFilter 或 基于 traits 的调度。
允许用户通过传递 JSON 格式的调度提示来构建自定义过滤器。支持以下运算符
=<>in<=>=not或者和
与大多数依赖于通过调度提示提供的信息的其他过滤器不同,此过滤器会过滤 HostState 类中的属性,例如以下变量
$free_ram_mb$free_disk_mb$hypervisor_hostname$total_usable_ram_mb$vcpus_total$vcpus_used
使用 openstack server create 命令,使用 --hint 标志
$ openstack server create --image 827d564a-e636-4fc4-a376-d36f7ebe1747 \
--flavor 1 --hint query='[">=","$free_ram_mb",1024]' server1
使用 API 时,使用 os:scheduler_hints 键
{
"server": {
"name": "server-1",
"imageRef": "cedef40a-ed67-4d10-800e-17455edce175",
"flavorRef": "1"
},
"os:scheduler_hints": {
"query": "[\">=\",\"$free_ram_mb\",1024]"
}
}
MetricsFilter¶
与 MetricsWeigher 权重器一起使用。过滤掉未报告在 metrics.weight_setting 中指定的指标的主机,从而确保权重器不会因这些主机而失败。
NUMATopologyFilter¶
基于通过 flavor 的 extra_specs 和镜像属性指定的 NUMA 拓扑过滤主机,具体细节请参见 CPU 拓扑。过滤器将尝试匹配实例的 NUMA 单元与主机的 NUMA 单元的完全匹配。它将考虑每个主机 NUMA 单元的标准过度订阅限制,并相应地为计算主机提供限制。
如果使用依赖于 NUMA 的功能(例如实例 NUMA 拓扑或 CPU pinning)的实例,则此过滤器至关重要。
注意
如果实例未定义拓扑,则将考虑任何主机。如果实例定义了拓扑,则仅考虑支持 NUMA 的主机。
NumInstancesFilter¶
基于主机上运行的实例数量过滤主机。如果主机上运行的实例数量超过 filter_scheduler.max_instances_per_host 配置选项指定的数量,则过滤掉这些主机。
PciPassthroughFilter¶
如果主机具有满足 flavor 的 extra_specs 属性中的设备请求,则此过滤器会在主机上调度实例。
如果使用具有 PCI 设备请求的实例或主机上使用基于 SR-IOV 的网络,则此过滤器至关重要。
SameHostFilter¶
将实例调度到与一组实例中的所有其他实例相同的宿主机上。要利用此过滤器,请求者必须传递一个调度提示,使用 same_host 作为键,并使用实例 UUID 列表作为值。此过滤器与 DifferentHostFilter 相反。
例如,在使用 openstack server create 命令时,使用 --hint 标志
$ openstack server create \
--image cedef40a-ed67-4d10-800e-17455edce175 --flavor 1 \
--hint same_host=a0cf03a5-d921-4877-bb5c-86d26cf818e1 \
--hint same_host=8c19174f-4220-44f0-824a-cd1eeef10287 \
server-1
使用 API 时,使用 os:scheduler_hints 键
{
"server": {
"name": "server-1",
"imageRef": "cedef40a-ed67-4d10-800e-17455edce175",
"flavorRef": "1"
},
"os:scheduler_hints": {
"same_host": [
"a0cf03a5-d921-4877-bb5c-86d26cf818e1",
"8c19174f-4220-44f0-824a-cd1eeef10287"
]
}
}
ServerGroupAffinityFilter¶
将属于同一服务器组的实例限制在相同的宿主机上。要利用此过滤器,请求者必须创建一个具有 affinity 策略的服务器组,并传递一个调度提示,使用 group 作为键,并使用服务器组 UUID 作为值。
例如,在使用 openstack server create 命令时,使用 --hint 标志
$ openstack server group create --policy affinity group-1
$ openstack server create --image IMAGE_ID --flavor 1 \
--hint group=SERVER_GROUP_UUID server-1
有关服务器组的更多信息,请参阅 服务器组。
ServerGroupAntiAffinityFilter¶
将属于同一服务器组的实例限制在不同的宿主机上。要利用此过滤器,请求者必须创建一个具有 anti-affinity 策略的服务器组,并传递一个调度提示,使用 group 作为键,并使用服务器组 UUID 作为值。
例如,在使用 openstack server create 命令时,使用 --hint 标志
$ openstack server group create --policy anti-affinity group-1
$ openstack server create --image IMAGE_ID --flavor 1 \
--hint group=SERVER_GROUP_UUID server-1
有关服务器组的更多信息,请参阅 服务器组。
SimpleCIDRAffinityFilter¶
待办事项
此过滤器是否仍然适用于 neutron?
基于主机 IP 子网范围调度实例。要利用此过滤器,请求者必须指定 CIDR 格式的有效 IP 地址范围,通过传递两个调度提示
build_near_host_ip子网中的第一个 IP 地址(例如,
192.168.1.1)cidr与子网对应的 CIDR(例如,
/24)
使用 openstack server create 命令时,使用 --hint 标志。例如,要指定 IP 子网 192.168.1.1/24
$ openstack server create \
--image cedef40a-ed67-4d10-800e-17455edce175 --flavor 1 \
--hint build_near_host_ip=192.168.1.1 --hint cidr=/24 \
server-1
使用 API 时,使用 os:scheduler_hints 键
{
"server": {
"name": "server-1",
"imageRef": "cedef40a-ed67-4d10-800e-17455edce175",
"flavorRef": "1"
},
"os:scheduler_hints": {
"build_near_host_ip": "192.168.1.1",
"cidr": "24"
}
}
权重¶
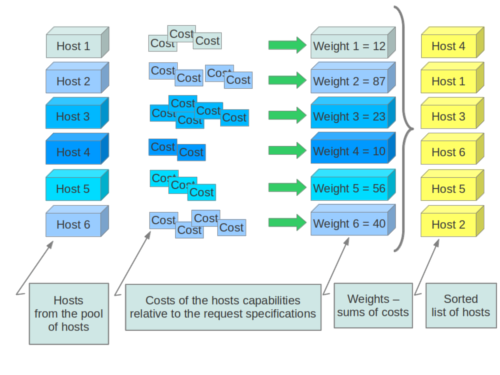
在资源化实例时,过滤器调度器会过滤并对可接受主机列表中的每个主机进行加权。每次调度器选择一个主机时,它都会虚拟地消耗其资源,后续选择会相应地进行调整。当客户请求相同数量的大量实例时,此过程很有用,因为会为每个请求的实例计算权重。
为了优先考虑一个权重器相对于另一个权重器,所有权重器都必须定义一个将在计算节点权重之前应用的乘数。所有权重都会在预先进行归一化,以便可以轻松应用乘数。因此,对象的最终权重将是
weight = w1_multiplier * norm(w1) + w2_multiplier * norm(w2) + ...
主机基于以下配置选项进行加权
RAMWeigher¶
基于计算节点上可用 RAM 计算权重。权重最大的获胜。如果乘数 filter_scheduler.ram_weight_multiplier 为负数,则可用 RAM 最少的宿主机将获胜(适用于堆叠宿主机,而不是分散)。
从 Stein 版本开始,如果在聚合中找到具有键 ram_weight_multiplier 的值,则将选择该值作为 RAM 权重乘数。否则,它将回退到 filter_scheduler.ram_weight_multiplier。如果在宿主机聚合元数据中找到多个值,则将使用最小值。
CPUWeigher¶
基于计算节点上可用的 vCPU 计算权重。权重最大的获胜。如果乘数 filter_scheduler.cpu_weight_multiplier 为负数,则可用 CPU 最少的宿主机将获胜(适用于堆叠宿主机,而不是分散)。
从 Stein 版本开始,如果在聚合中找到具有键 cpu_weight_multiplier 的值,则将选择该值作为 CPU 权重乘数。否则,它将回退到 filter_scheduler.cpu_weight_multiplier。如果在宿主机聚合元数据中找到多个值,则将使用最小值。
DiskWeigher¶
根据可用磁盘空间对主机进行加权和排序,权重最大的获胜。如果乘数为负数,则可用磁盘空间最少的宿主机将获胜(适用于堆叠宿主机,而不是分散)。
从 Stein 版本开始,如果在聚合中找到具有键 disk_weight_multiplier 的值,则将选择该值作为磁盘权重乘数。否则,它将回退到 filter_scheduler.disk_weight_multiplier。如果在宿主机聚合元数据中找到多个值,则将使用最小值。
MetricsWeigher¶
此权重器可以基于计算节点主机的各种指标计算权重。要加权的指标及其权重比例使用 metrics.weight_setting 配置选项指定。例如
[metrics]
weight_setting = name1=1.0, name2=-1.0
可以使用 metrics.required 和 metrics.weight_of_unavailable 配置选项分别指定所需的指标以及不可用指标的权重。
从 Stein 版本开始,如果在聚合中找到具有键 metrics_weight_multiplier 的值,则将选择该值作为指标权重乘数。否则,它将回退到 metrics.weight_multiplier。如果在宿主机聚合元数据中找到多个值,则将使用最小值。
IoOpsWeigher¶
权重器可以基于计算节点主机的负载计算权重。通过检查处于 building vm_state 或以下 task_state 中的实例数量来计算:resize_migrating、rebuilding、resize_prep、image_snapshot、image_backup、rescuing 或 unshelving。默认情况下,倾向于选择负载较轻的计算主机。如果乘数为正数,则权重器更喜欢选择负载较重的计算主机,权重效果与默认效果相反。
从 Stein 版本开始,如果在聚合中找到具有键 io_ops_weight_multiplier 的值,则将选择该值作为 IO ops 权重乘数。否则,它将回退到 filter_scheduler.io_ops_weight_multiplier。如果在宿主机聚合元数据中找到多个值,则将使用最小值。
PCIWeigher¶
根据主机上 PCI 设备数量和实例请求的 PCI 设备数量计算权重。例如,给定三台主机——一台具有单个 PCI 设备,一台具有多个 PCI 设备,一台没有 PCI 设备——nova 应该根据实例的需求对这些主机进行不同的优先级排序。如果实例请求单个 PCI 设备,则应优先选择第一台主机。同样,如果实例请求多个 PCI 设备,则应优先选择第二台主机。最后,如果实例不请求 PCI 设备,则应优先选择最后一台主机。
为了使上述内容具有任何价值,至少需要启用其中一个 PciPassthroughFilter 或 NUMATopologyFilter 过滤器。
从 Stein 版本开始,如果在聚合中找到具有键 pci_weight_multiplier 的值,则将选择该值作为 PCI 权重乘数。否则,它将回退到 filter_scheduler.pci_weight_multiplier。如果在主机聚合元数据中找到多个值,则将使用最小值。
重要提示
此称重器的乘数仅允许正值,因为负值会迫使非 PCI 实例远离非 PCI 主机,从而导致未来的调度问题。
ServerGroupSoftAffinityWeigher¶
该称重器可以根据在同一服务器组上运行的实例数量计算权重。最大的权重定义了新实例的首选主机。对于乘数,计算中仅允许正值。
从 Stein 版本开始,如果在聚合中找到具有键 soft_affinity_weight_multiplier 的值,则将选择该值作为软亲和力权重乘数。否则,它将回退到 filter_scheduler.soft_affinity_weight_multiplier。如果在主机聚合元数据中找到多个值,则将使用最小值。
ServerGroupSoftAntiAffinityWeigher¶
该称重器可以根据在同一服务器组上运行的实例数量计算权重,将其作为负值。最大的权重定义了新实例的首选主机。对于乘数,计算中仅允许正值。
从 Stein 版本开始,如果在聚合中找到具有键 soft_anti_affinity_weight_multiplier 的值,则将选择该值作为软反亲和力权重乘数。否则,它将回退到 filter_scheduler.soft_anti_affinity_weight_multiplier。如果在主机聚合元数据中找到多个值,则将使用最小值。
BuildFailureWeigher¶
根据最近的启动失败次数对主机进行称重。它会考虑构建失败计数器,并可以对最近失败的主机进行负权重。这避免了完全将计算节点从轮换中移除。
从 Stein 版本开始,如果在聚合中找到具有键 build_failure_weight_multiplier 的值,则将选择该值作为构建失败权重乘数。否则,它将回退到 filter_scheduler.build_failure_weight_multiplier。如果在主机聚合元数据中找到多个值,则将使用最小值。
重要提示
filter_scheduler.build_failure_weight_multiplier 选项默认设置为非常高的值。这旨在抵消其他已启用称重器由于可用资源而给出的权重,从而使此称重器具有优先级。但是,并非所有构建失败都意味着主机本身存在问题——可能是用户错误——但失败仍然会被计数。如果您发现主机经常报告构建失败并有效地在调度期间被排除,您可能希望降低乘数值。
CrossCellWeigher¶
在 21.0.0 版本中添加: (Ussuri)
根据主机所在的 cell 对主机进行称重。在移动实例时,优先选择“本地”cell。
如果在聚合中找到具有键 cross_cell_move_weight_multiplier 的值,则将选择该值作为跨 cell 移动权重乘数。否则,它将回退到 filter_scheduler.cross_cell_move_weight_multiplier。如果在主机聚合元数据中找到多个值,则将使用最小值。
HypervisorVersionWeigher¶
在 28.0.0 版本中添加: (Bobcat)
根据 virt 驱动程序报告的 hypervisor 版本对主机进行称重。
虽然所有 virt 驱动程序的 hypervisor_version 字段都是一个整数,但每个 nova virt 驱动程序使用不同的算法将特定于 hypervisor 的版本序列转换为整数。因此,这些值不能直接比较具有不同 hypervisor 的主机。
例如,ironic virt 驱动程序使用 ironic API 微版本作为给定节点的 hypervisor 版本。libvirt 驱动程序使用 libvirt 版本,例如 Libvirt 7.1.123 变为 700100123,而 Ironic 1.82 变为 1。
如果您有混合的 virt 驱动程序部署(ironic 与非 ironic 的情况),则无需执行任何特殊操作。ironic 节点使用自定义资源类进行调度,因此 ironic flavor 将永远不会与非 ironic 计算节点匹配。
如果部署有多个非 ironic virt 驱动程序,建议使用聚合将主机按 virt 驱动程序分组。虽然这并非绝对必要,但为了避免对某个 virt 驱动程序产生偏差,这是可取的。请参阅 通过隔离聚合过滤主机 和 AggregateImagePropertiesIsolation 以获取更多信息。
HypervisorVersionWeigher 的默认行为是选择较新的主机。如果您希望反转该行为,请将 filter_scheduler.hypervisor_version_weight_multiplier 选项设置为负数,则称重效果将与默认效果相反。
NumInstancesWeigher¶
在 28.0.0 版本中添加: (Bobcat)
此称重器比较主机并根据其实例数量对主机进行排序。默认情况下,该称重器不执行任何操作,但可以通过修改 filter_scheduler.num_instances_weight_multiplier 的值来更改其行为。正值将优先选择具有更多实例的主机(打包策略),而负值将遵循扩散策略,优先选择具有较少实例的主机。
ImagePropertiesWeigher¶
在 31.0.0 版本中添加: (Epoxy)
此称重器比较主机并根据现有实例的镜像属性对主机进行排序。默认情况下,该称重器不执行任何操作,但可以通过修改 filter_scheduler.image_props_weight_multiplier 的值来更改其行为。正值将优先选择具有相同镜像属性的主机(打包策略),而负值将遵循扩散策略,优先选择尚未具有这些镜像属性的实例的主机。
您还可以使用 filter_scheduler.image_props_weight_setting 配置选项来定义您希望称重的确切属性。例如,如果您配置 os_distro 为 2,hw_machine_type 为 0,则后者属性将不会被称重,而前者将计数两次。假设您配置 os_distro=10,os_secure_boot=1,os_require_quiesce=0,那么当请求使用具有这些属性的镜像的实例时,对于主机上已经运行的实例,如果至少有一个属性匹配,则相同的 os_distro 值(例如 windows 或 linux)的匹配将计数 10 倍,而相同的 os_secure_boot 值(例如 true 或 false)的匹配将计数 1 倍,而任何关于相同的 os_require_quiesce 值的匹配将不会计数。如果您定义 filter_scheduler.image_props_weight_setting,那么用于启动的镜像中的任何属性都不会被计数,除非在选项值中提供。最终的主机权重将乘以 filter_scheduler.image_props_weight_multiplier 的值。
感知利用率的调度¶
警告
此功能测试不足,可能无法按预期工作。它可能会在未来的版本中被删除。请自行承担风险使用。
可以使用高级调度决策来调度实例。这些决策基于增强的使用统计信息,包括内存缓存利用率、内存带宽利用率或网络带宽利用率等数据。默认情况下,此功能已禁用。管理员可以通过在配置文件中使用 metrics.weight_setting 配置选项来配置配置文件的度量权重。例如,要将 metric1 配置为 ratio1,将 metric2 配置为 ratio2
[metrics]
weight_setting = "metric1=ratio1, metric2=ratio2"
分配比例¶
分配比例允许过度承诺主机资源。以下配置选项存在于控制此过度承诺资源的每个计算节点的分配比例。
cpu_allocation_ratio允许覆盖计算节点的VCPU库存分配比例ram_allocation_ratio允许覆盖计算节点的MEMORY_MB库存分配比例disk_allocation_ratio允许覆盖计算节点的DISK_GB库存分配比例
在 19.0.0 Stein 版本之前,如果未设置,cpu_allocation_ratio 默认值为 16.0,ram_allocation_ratio 默认值为 1.5,disk_allocation_ratio 默认值为 1.0。
从 19.0.0 Stein 版本开始,以下配置选项控制新计算节点记录的初始分配比例值
initial_cpu_allocation_ratio新计算节点记录的初始 VCPU 库存分配比例,默认为 16.0initial_ram_allocation_ratio新计算节点记录的初始 MEMORY_MB 库存分配比例,默认为 1.5initial_disk_allocation_ratio新计算节点记录的初始 DISK_GB 库存分配比例,默认为 1.0
从 27.0.0 Antelope 版本开始,以下默认值用于新计算节点的初始分配比例值
initial_cpu_allocation_ratio新计算节点记录的初始 VCPU 库存分配比例,默认为 4.0initial_ram_allocation_ratio新计算节点记录的初始 MEMORY_MB 库存分配比例,默认为 1.0initial_disk_allocation_ratio新计算节点记录的初始 DISK_GB 库存分配比例,默认为 1.0
调度注意事项¶
分配比例配置用于向 placement 服务报告计算节点 资源提供者库存 以及在调度期间。
使用场景¶
由于可以通过 nova 配置和 placement API 设置分配比例,因此可能难以知道应该使用哪个。这实际上取决于您的场景。以下是一些常见的场景。
当部署者想要始终为计算节点上的资源设置覆盖值时,部署者应确保将
DEFAULT.cpu_allocation_ratio、DEFAULT.ram_allocation_ratio和DEFAULT.disk_allocation_ratio配置选项设置为非 None 值。这将使nova-compute服务覆盖通过 placement REST API 设置的任何外部分配比例值。当部署者想要为计算节点分配比例设置一个初始值,但希望允许管理员稍后在不进行任何配置文件更改的情况下调整此值时,部署者应设置
DEFAULT.initial_cpu_allocation_ratio、DEFAULT.initial_ram_allocation_ratio和DEFAULT.initial_disk_allocation_ratio配置选项,然后使用 placement REST API(或 osc-placement 命令行界面)管理分配比例。例如$ openstack resource provider inventory set \ --resource VCPU:allocation_ratio=1.0 \ --amend 815a5634-86fb-4e1e-8824-8a631fee3e06
当部署者想要始终使用 placement API 设置分配比例时,部署者应确保将
DEFAULT.cpu_allocation_ratio、DEFAULT.ram_allocation_ratio和DEFAULT.disk_allocation_ratio配置选项设置为 None,然后使用 placement REST API(或 osc-placement 命令行界面)管理分配比例。此场景是 bug 1804125 的解决方法。
版本 19.0.0 中更改: (Stein)
配置选项 DEFAULT.initial_cpu_allocation_ratio、DEFAULT.initial_ram_allocation_ratio 和 DEFAULT.initial_disk_allocation_ratio 是在 Stein 中引入的。在此版本之前,将 DEFAULT.cpu_allocation_ratio、DEFAULT.ram_allocation_ratio 或 DEFAULT.disk_allocation_ratio 设置为非空值,将确保用户配置的值始终被覆盖。
特定于 Hypervisor 的注意事项¶
Nova 提供了三个配置选项,可用于预留一些不会被实例消耗的资源,无论这些资源是否被过度提交
一些 virt 驱动程序可能会受益于使用这些选项来考虑特定于 hypervisor 的开销。
Cells 的注意事项¶
默认情况下,cells 启用用于调度新实例,但它们可以被禁用(阻止新的调度到 cell)。这对于用户在执行 cell 维护、故障或其他干预时可能很有用。需要注意的是,创建预禁用 cells 和启用/禁用现有 cells 应该在 nova-scheduler 服务的重启或 SIGHUP 之后进行,才能使更改生效。
命令行界面¶
nova-manage 命令行客户端支持 cell-disable 相关的命令。要启用或禁用 cell,请使用 nova-manage cell_v2 update_cell,要创建预禁用 cells,请使用 nova-manage cell_v2 create_cell。有关命令用法的详细信息,请参阅 Cells v2 命令 man 页面。
计算能力作为 traits¶
版本 19.0.0 中添加: (Stein)
nova-compute 服务将根据其计算驱动程序的功能向 placement 服务报告某些 COMPUTE_* traits。这些 traits 将与该计算服务的资源提供程序关联。可以通过在 flavor 中配置 Required traits 或 Forbidden traits,在调度期间使用这些 traits。例如,如果您有一个包含一组支持多卷附加的计算节点的 host aggregate,您可以将 flavor 限制到该 aggregate,方法是在 flavor 中添加 trait:COMPUTE_VOLUME_MULTI_ATTACH=required extra spec,然后像 正常 一样将 flavor 限制到 aggregate。
这是一个 libvirt 计算节点资源提供程序的示例,它将一些 CPU 功能作为 traits 暴露出来,将驱动程序功能作为 traits 暴露出来,以及一个以 CUSTOM_ 前缀开头的自定义 trait
$ openstack --os-placement-api-version 1.6 resource provider trait list \
> d9b3dbc4-50e2-42dd-be98-522f6edaab3f --sort-column name
+---------------------------------------+
| name |
+---------------------------------------+
| COMPUTE_DEVICE_TAGGING |
| COMPUTE_NET_ATTACH_INTERFACE |
| COMPUTE_NET_ATTACH_INTERFACE_WITH_TAG |
| COMPUTE_TRUSTED_CERTS |
| COMPUTE_VOLUME_ATTACH_WITH_TAG |
| COMPUTE_VOLUME_EXTEND |
| COMPUTE_VOLUME_MULTI_ATTACH |
| CUSTOM_IMAGE_TYPE_RBD |
| HW_CPU_X86_MMX |
| HW_CPU_X86_SSE |
| HW_CPU_X86_SSE2 |
| HW_CPU_X86_SVM |
+---------------------------------------+
Rules
与能力定义的 traits 关联一些规则。
计算服务“拥有”这些 traits,并在
nova-compute服务启动时以及update_available_resource定期任务运行时添加/删除它们,运行间隔由配置选项update_resources_interval控制。计算服务不会删除外部在资源提供程序上设置的任何自定义 traits,例如上面的
CUSTOM_IMAGE_TYPE_RBDtrait 示例。如果从资源提供程序外部删除了计算拥有的 traits,例如运行
openstack resource provider trait delete <rp_uuid>,则计算服务将在重启或 SIGHUP 时重新添加其 traits。如果在资源提供程序上设置了驱动程序不支持的计算 trait,例如在驱动程序不支持该功能时添加
COMPUTE_VOLUME_EXTENDtrait,则计算服务将在重启或 SIGHUP 时自动删除不支持的 trait。计算能力 traits 是在 os-traits 库中定义的标准 traits。
有关能力和 traits 的更多信息 可以在 技术参考深入探讨部分 中找到。
编写自己的 Filter¶
要创建您自己的 filter,您必须从 BaseHostFilter 继承并实现一种方法:host_passes。此方法应在 host 通过 filter 时返回 True,否则返回 False。它接受两个参数
HostState对象允许获取 host 的属性RequestSpec对象描述用户请求,包括 flavor、image 和 scheduler hints
有关这些对象及其各自属性的更多详细信息,请参阅代码库(至少通过查看其他 filter 的代码)或在 #openstack-nova IRC 频道中寻求帮助。
此外,如果您的自定义 filter 使用非标准 extra specs,则必须注册这些 extra specs 的验证器。可以在 nova.api.validation.extra_specs 模块中找到验证器的示例。这些应通过 nova.api.extra_spec_validator entrypoint 注册。
包含您的自定义 filter 的模块必须打包并在 nova controllers(特别是 nova-scheduler 和 nova-api-wsgi 服务)可用的相同环境中提供。例如,考虑以下示例包,这是基于 setuptools 的标准 Python 包的 最小结构
acmefilter/
acmefilter/
__init__.py
validators.py
setup.py
其中 __init__.py 包含
from oslo_log import log as logging
from nova.scheduler import filters
LOG = logging.getLogger(__name__)
class AcmeFilter(filters.BaseHostFilter):
def host_passes(self, host_state, spec_obj):
extra_spec = spec_obj.flavor.extra_specs.get('acme:foo')
LOG.info("Extra spec value was '%s'", extra_spec)
# do meaningful stuff here...
return True
validators.py 包含
from nova.api.validation.extra_specs import base
def register():
validators = [
base.ExtraSpecValidator(
name='acme:foo',
description='My custom extra spec.'
value={
'type': str,
'enum': [
'bar',
'baz',
],
},
),
]
return validators
setup.py 包含
from setuptools import setup
setup(
name='acmefilter',
version='0.1',
description='My custom filter',
packages=[
'acmefilter'
],
entry_points={
'nova.api.extra_spec_validators': [
'acme = acmefilter.validators',
],
},
)
要启用此功能,您需要在 nova.conf 中设置以下内容
[filter_scheduler]
available_filters = nova.scheduler.filters.all_filters
available_filters = acmefilter.AcmeFilter
enabled_filters = ComputeFilter,AcmeFilter
注意
您必须使用 filter_scheduler.available_filters 配置选项将自定义 filter 添加到可用 filter 列表中,除了通过 filter_scheduler.enabled_filters 配置选项启用它们。后者默认值 nova.scheduler.filters.all_filters 仅包含 nova 提供的 filter。
使用这些设置,所有标准 nova filter 和自定义 AcmeFilter filter 都可用于 scheduler,但只有 ComputeFilter 和 AcmeFilter 将在每个请求中使用。
编写自己的 weigher¶
要创建您自己的 weigher,您必须从 BaseHostFilter 继承。一个 weigher 可以实现 weight_multiplier 和 _weight_object 方法,也可以只实现 weight_objects 方法。weight_objects 方法仅在您需要访问所有对象才能计算权重时被覆盖,并且它只是返回权重列表,而不直接修改对象的权重,因为最终权重由 weight.BaseWeightHandler 归一化和计算。
