使用 Beats 收集指标安装 ELK¶
- tags:
openstack, ansible
关于此仓库¶
这套 playbook 将部署一个弹性堆栈集群(Elasticsearch、Logstash、Kibana),并使用 Beats 收集主机上的指标,并将它们存储到弹性堆栈中。
这些 playbook 需要 Ansible 2.5+。
弹性堆栈基础设施的高层概述,这些 playbook 将构建和运行于此之上。

OpenStack-Ansible 集成¶
这些 playbook 可以用作独立清单,也可以作为 OpenStack-Ansible 部署的集成部分。有关独立清单的简单示例,请参阅 [test-inventory.yml](tests/inventory/test-inventory.yml)。
可选 | 负载均衡器配置¶
- 配置 Elasticsearch 端点
虽然弹性堆栈集群不需要负载均衡器来扩展,但当使用外部工具访问 Elasticsearch 集群时,它很有用。像 OSProfiler、Grafana 等工具都将受益于能够使用负载均衡器与 Elasticsearch 交互。这提供了更好的容错能力,尤其与连接到单个节点相比。可以将以下部分添加到 haproxy_extra_services 列表中以创建 Elasticsearch 后端。用于连接到 Elasticsearch 的入口端口是 9201。后端端口是 9200。如果设置了此后端,请确保在 CLI 或在运行时将调用的已知变量文件中设置 internal_lb_vip_address。如果使用 HAProxy,请编辑 /etc/openstack_deploy/user_variables.yml 文件并添加以下行。
haproxy_extra_services:
- service:
haproxy_service_name: elastic-logstash
haproxy_ssl: False
haproxy_backend_nodes: "{{ groups['Kibana'] | default([]) }}" # Kibana nodes are also Elasticsearch coordination nodes
haproxy_port: 9201 # This is set using the "elastic_hap_port" variable
haproxy_check_port: 9200 # This is set using the "elastic_port" variable
haproxy_backend_port: 9200 # This is set using the "elastic_port" variable
haproxy_balance_type: tcp
- 配置 Kibana 端点
建议使用负载均衡器与 Kibana 一起使用。与 Elasticsearch 类似,负载均衡器不是必需的,但是如果没有它,用户需要直接连接到单个 Kibana 节点才能访问仪表板。如果存在负载均衡器,它可以为用户提供一个高可用性地址,以访问 Kibana 节点池,这将提供更好的用户体验。如果使用 HAProxy,请编辑 /etc/openstack_deploy/user_variables.yml 文件并添加以下行。
haproxy_extra_services:
- service:
haproxy_service_name: Kibana
haproxy_ssl: False
haproxy_backend_nodes: "{{ groups['Kibana'] | default([]) }}"
haproxy_port: 81 # This is set using the "Kibana_nginx_port" variable
haproxy_balance_type: tcp
- 配置 APM 端点
建议使用负载均衡器来将应用程序性能监控数据提交到 APM 服务器。负载均衡器将提供一个高可用性地址,APM 客户端可以使用该地址连接到 APM 节点池。如果使用 HAProxy,请编辑 /etc/openstack_deploy/user_variables.yml 文件并添加以下行
haproxy_extra_services:
- service:
haproxy_service_name: apm-server
haproxy_ssl: False
haproxy_backend_nodes: "{{ groups['apm-server'] | default([]) }}"
haproxy_port: 8200 # this is set using the "apm_port" variable
haproxy_balance_type: tcp
可选 | 将 OSProfiler 添加到 OpenStack-Ansible 部署¶
要在 openstack 中初始化 OSProfiler 模块,可以将以下覆盖应用于用户变量文件。hmac 密钥需要在整个环境中保持一致。
初始化整个 OpenStack-Ansible 部署中的 OSProfiler 模块的完整示例。
profiler_overrides: &os_profiler
profiler:
enabled: true
trace_sqlalchemy: true
hmac_keys: "UNIQUE_HMACKEY" # This needs to be set consistently throughout the deployment
connection_string: "Elasticsearch://{{ internal_lb_vip_address }}:9201"
es_doc_type: "notification"
es_scroll_time: "2m"
es_scroll_size: "10000"
filter_error_trace: "false"
aodh_aodh_conf_overrides: *os_profiler
barbican_config_overrides: *os_profiler
ceilometer_ceilometer_conf_overrides: *os_profiler
cinder_cinder_conf_overrides: *os_profiler
designate_designate_conf_overrides: *os_profiler
glance_glance_api_conf_overrides: *os_profiler
gnocchi_conf_overrides: *os_profiler
heat_heat_conf_overrides: *os_profiler
horizon_config_overrides: *os_profiler
ironic_ironic_conf_overrides: *os_profiler
keystone_keystone_conf_overrides: *os_profiler
magnum_config_overrides: *os_profiler
neutron_neutron_conf_overrides: *os_profiler
nova_nova_conf_overrides: *os_profiler
octavia_octavia_conf_overrides: *os_profiler
rally_config_overrides: *os_profiler
sahara_conf_overrides: *os_profiler
swift_swift_conf_overrides: *os_profiler
tacker_tacker_conf_overrides: *os_profiler
trove_config_overrides: *os_profiler
如果部署者希望使用多个密钥,可以使用逗号分隔的列表来执行此操作。
profiler_overrides: &os_profiler
profiler:
hmac_keys: "key1,key2"
要将 OSProfiler 部分添加到现有的覆盖集合中,可以使用 yaml 标签将 yaml 部分添加到给定的哈希中或动态地附加到给定的哈希中。
profiler_overrides: &os_profiler
profiler:
enabled: true
hmac_keys: "UNIQUE_HMACKEY" # This needs to be set consistently throughout the deployment
connection_string: "Elasticsearch://{{ internal_lb_vip_address }}:9201"
es_doc_type: "notification"
es_scroll_time: "2m"
es_scroll_size: "10000"
filter_error_trace: "false"
# Example to merge the os_profiler tag to into an existing override hash
nova_nova_conf_overrides:
section1_override:
key: "value"
<<: *os_profiler
虽然默认情况下 osprofiler 和 Elasticsearch 库应安装在所有虚拟环境中,但可能在给定的部署中缺少它们。要安装这些依赖项,而无需调用 repo-build,可以使用以下 adhoc Ansible 命令。
Elasticsearch python 库的版本应与环境中部署的 Elasticsearch 的主要版本匹配。
ansible -m shell -a 'find /openstack/venvs/* -maxdepth 0 -type d -exec {}/bin/pip install osprofiler "elasticsearch>=6.0.0,<7.0.0" --isolated \;' all
一旦覆盖到位,openstack-ansible playbook 将需要重新运行。要简单地将这些选项注入到系统中,部署者可以使用所有 os_ 角色中都包含的 *-config 标签。以下示例将在 ALL openstack playbook 上运行 config 标签。
openstack-ansible setup-openstack.yml --tags "$(cat setup-openstack.yml | grep -wo 'os-.*' | awk -F'-' '{print $2 "-config"}' | tr '\n' ',')"
一旦 OSProfiler 模块初始化,就可以使用各种 openstack 客户端中的 –profile 或 –os-profile 选项以及给定的 hmac 密钥之一,按需分析任务。
旧版分析示例命令。
glance --profile key1 image-list
现代分析示例命令,需要 python-openstackclient >= 3.4.1 和 osprofiler 库。
openstack --os-profile key2 image list
如果客户端库未安装在与 python-openstackclient 客户端相同的路径中,请运行以下命令安装所需的库。
pip install osprofiler
可选 | 运行 haproxy-install playbook¶
cd /opt/openstack-ansible/playbooks/
openstack-ansible haproxy-install.yml --tags=haproxy-service-config
设置 | 系统配置¶
克隆 elk-osa 仓库
cd /opt
git clone https://github.com/openstack/openstack-ansible-ops
将 env.d 文件复制到位
cd /opt/openstack-ansible-ops/elk_metrics_7x
cp env.d/elk.yml /etc/openstack_deploy/env.d/
将 conf.d 文件复制到位
cp conf.d/elk.yml /etc/openstack_deploy/conf.d/
在 elk.yml 中,将您的日志记录主机列在 elastic-logstash_hosts 下,以在多个容器中创建 Elasticsearch 集群,并将一个日志记录主机列在 kibana_hosts 下,以创建 Kibana 容器
vi /etc/openstack_deploy/conf.d/elk.yml
创建容器
cd /opt/openstack-ansible/playbooks
openstack-ansible lxc-containers-create.yml --limit elk_all
部署 | 使用嵌入式 Ansible 安装¶
如果此操作是在已经安装了 Ansible 但与这些 playbook 不兼容的系统上执行的,可以获取嵌入式版本的 Ansible,然后再执行 playbook,方法是获取 bootstrap-embedded-ansible.sh 脚本。
source bootstrap-embedded-ansible.sh
部署 | 手动解析依赖项¶
此 playbook 具有外部角色依赖项。如果 Ansible 未使用 bootstrap-ansible.sh 脚本安装,可以使用 ansible-galaxy 命令和 ansible-role-requirements.yml 文件解析这些依赖项。
示例 galaxy 执行
ansible-galaxy install -r ansible-role-requirements.yml
设置依赖项后,请确保使用环境变量 ANSIBLE_ACTION_PLUGINS 或使用 ansible.cfg 文件将操作插件路径设置为 config_template 操作目录的位置。
部署 | 环境¶
在 elastic-logstash 容器上安装 master/data Elasticsearch 节点,部署 logstash,部署 Kibana,然后部署所有 service beats。
cd /opt/openstack-ansible-ops/elk_metrics_7x
ansible-playbook site.yml $USER_VARS
如果系统上的 ansible 版本大于 2.5,可以使用 openstack-ansible 命令。这将自动获取 OSA 部署中主机所需的 group_vars。
您可能需要在运行之前收集 facts,
openstack -m setup elk_all将收集您需要的 facts。如果需要,添加
-e@/opt/openstack-ansible/inventory/group_vars/all/all.yml以导入足够的 OSA group 变量来定义 OpenStack 版本。Journalbeat 将部署到 Rocky 之前的版本中的所有主机/容器,以及 Rocky 之后的版本中的主机。如果未定义变量openstack_release,则默认行为是将 Journalbeat 部署到主机。或者,如果使用嵌入式 ansible,可以创建符号链接以包含所有 OSA group_vars。默认情况下,这些在嵌入式 ansible 中不可用,并且可以符号链接到 ops 仓库中。
ln -s /opt/openstack-ansible/inventory/group_vars /opt/openstack-ansible-ops/elk_metrics_7x/group_vars
此仓库中的各个 playbook 可以随时独立运行。
架构 | 数据流¶
此图概述了弹性堆栈部署中的数据流。

可选 | 启用 uwsgi 统计信息¶
可以使用配置覆盖来使 uwsgi 统计信息在 unix 域套接字上可用。任何 /tmp/<service>-uwsgi-stats.sock 都将被 Metricsbeat 拾取。
keystone_uwsgi_ini_overrides:
uwsgi:
stats: "/tmp/keystone-uwsgi-stats.sock"
cinder_api_uwsgi_ini_overrides:
uwsgi:
stats: "/tmp/cinder-api-uwsgi-stats.sock"
glance_api_uwsgi_ini_overrides:
uwsgi:
stats: "/tmp/glance-api-uwsgi-stats.sock"
heat_api_uwsgi_ini_overrides:
uwsgi:
stats: "/tmp/heat-api-uwsgi-stats.sock"
heat_api_cfn_init_overrides:
uwsgi:
stats: "/tmp/heat-api-cfn-uwsgi-stats.sock"
nova_api_metadata_uwsgi_ini_overrides:
uwsgi:
stats: "/tmp/nova-api-metadata-uwsgi-stats.sock"
nova_api_os_compute_uwsgi_ini_overrides:
uwsgi:
stats: "/tmp/nova-api-os-compute-uwsgi-stats.sock"
nova_placement_uwsgi_ini_overrides:
uwsgi:
stats: "/tmp/nova-placement-uwsgi-stats.sock"
octavia_api_uwsgi_ini_overrides:
uwsgi:
stats: "/tmp/octavia-api-uwsgi-stats.sock"
sahara_api_uwsgi_ini_overrides:
uwsgi:
stats: "/tmp/sahara-api-uwsgi-stats.sock"
ironic_api_uwsgi_ini_overrides:
uwsgi:
stats: "/tmp/ironic-api-uwsgi-stats.sock"
magnum_api_uwsgi_ini_overrides:
uwsgi:
stats: "/tmp/magnum-api-uwsgi-stats.sock"
要重新运行所有 openstack-ansible playbook 以启用这些统计信息,请使用 ${service_name}-config 标签在所有 os_ 角色上。 可以使用以下命令自动生成标签列表。
openstack-ansible setup-openstack.yml --tags "$(cat setup-openstack.yml | grep -wo 'os-.*' | awk -F'-' '{print $2 "-config"}' | tr '\n' ',')"
可选 | 添加 Kafka 输出格式¶
要将数据从 Logstash 发送到 Kafka,请创建 logstash_kafka_options 变量。此变量将用作生成器,并使用键/值对作为选项创建 Kafka 输出配置文件。
logstash_kafka_options:
codec: json
topic_id: "elk_kafka"
ssl_key_password: "{{ logstash_kafka_ssl_key_password }}"
ssl_keystore_password: "{{ logstash_kafka_ssl_keystore_password }}"
ssl_keystore_location: "/var/lib/logstash/{{ logstash_kafka_ssl_keystore_location | basename }}"
ssl_truststore_location: "/var/lib/logstash/{{ logstash_kafka_ssl_truststore_location | basename }}"
ssl_truststore_password: "{{ logstash_kafka_ssl_truststore_password }}"
bootstrap_servers:
- server1.local:9092
- server2.local:9092
- server3.local:9092
client_id: "elk_metrics_7x"
compression_type: "gzip"
security_protocol: "SSL"
id: "UniqueOutputID"
有关 Logstash Kafka 输出插件中所有可用选项的完整列表,请查看 以下文档。
- 可选配置
以下变量是可选的,对应于示例 logstash_kafka_options 变量。
logstash_kafka_ssl_key_password: "secrete"
logstash_kafka_ssl_keystore_password: "secrete"
logstash_kafka_ssl_truststore_password: "secrete"
# SSL certificates in Java KeyStore format
logstash_kafka_ssl_keystore_location: "/root/kafka/keystore.jks"
logstash_kafka_ssl_truststore_location: "/root/kafka/truststore.jks"
当使用 kafka 输出插件时,选项 logstash_kafka_ssl_keystore_location 和 logstash_kafka_ssl_truststore_location 将自动将本地 SSL 密钥复制到 logstash 节点。这些选项是字符串值,并假定部署节点可以本地访问这些文件。
可选 | 添加 Grafana 可视化¶
有关如何部署 grafana 的更多信息,请参阅 grafana 目录。部署 grafana 时,从 ELK 获取变量文件,以便自动将 grafana 连接到 Elasticsearch 数据存储并导入仪表板。包含变量文件就像添加 -e @../elk_metrics_7x/vars/variables.yml 到 grafana playbook 运行一样简单。
包含的仪表板。
在 grafana 目录中使用嵌入式 Ansible 的示例命令。
ansible-playbook ${USER_VARS} installGrafana.yml \
-e @../elk_metrics_7x/vars/variables.yml \
-e 'galera_root_user="root"' \
-e 'galera_address={{ internal_lb_vip_address }}'
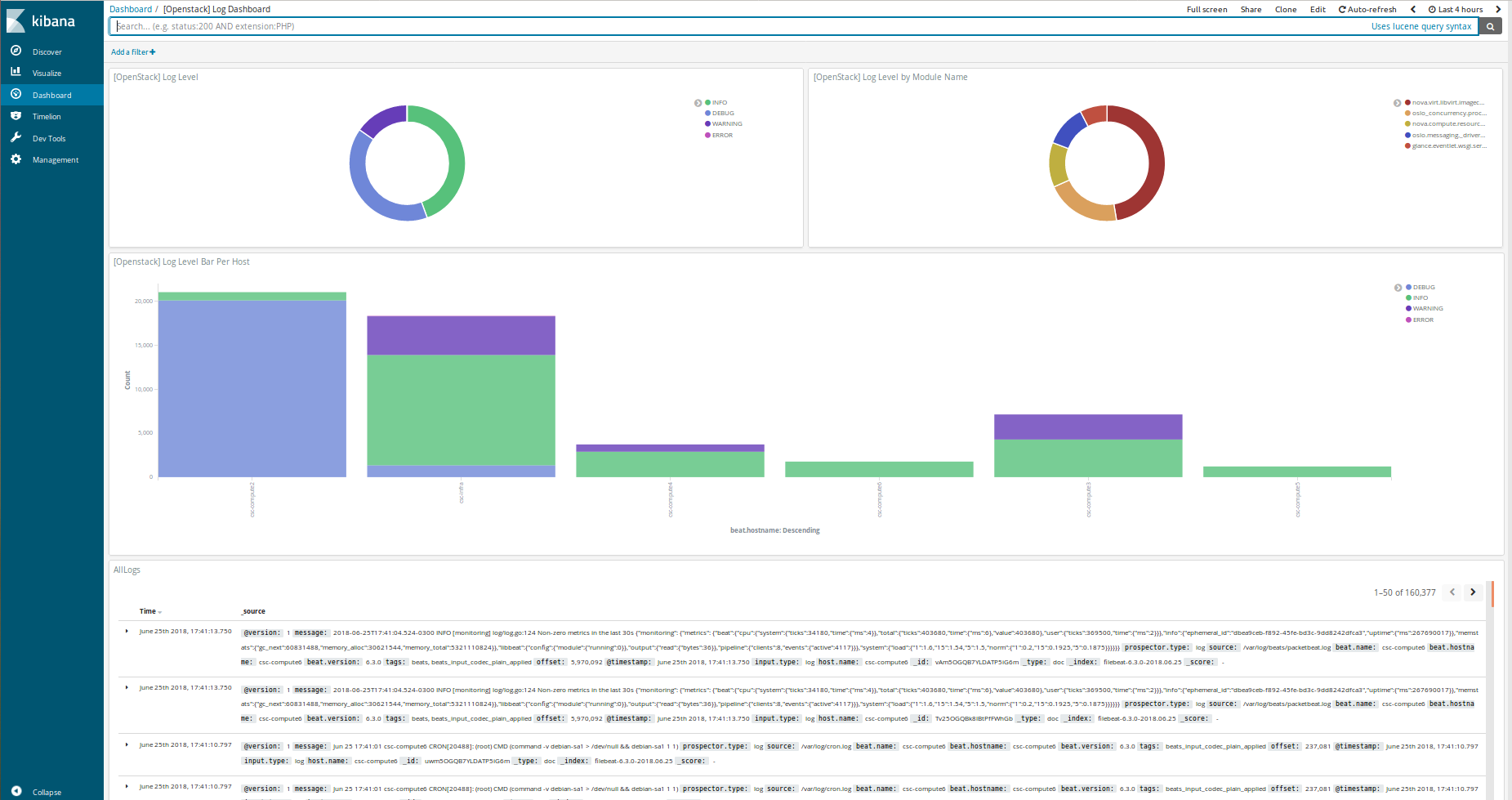
可选 | 添加 kibana 自定义仪表板¶
如果您想直接在 kibana 上使用自定义仪表板,可以运行下面的 playbook。该仪表板使用 filebeat 收集部署日志。
ansible-playbook setupKibanaDashboard.yml $USER_VARS
kibana 自定义仪表板概述
可选 | 自定义 Elasticsearch 集群配置¶
可以使用几个变量来增强集群配置,这些变量将强制节点使用给定的角色。默认情况下,所有节点都是数据和 ingest 适用的。
可用角色是 data、ingest 和 master。
elasticsearch_node_data:此变量将覆盖自动节点确定,并将给定节点设置为“data”节点。elasticsearch_node_ingest:此变量将覆盖自动节点确定并将给定节点设置为“ingest”节点。
elasticsearch_node_master:此变量将覆盖自动节点确定并将给定节点设置为“master”节点。
在 inventory 中设置覆盖选项的示例。
hosts:
children:
elastic:
hosts:
elk1:
ansible_host: 10.0.0.1
ansible_user: root
elasticsearch_node_master: true
elasticsearch_node_data: false
elasticsearch_node_ingest: false
elk2:
ansible_host: 10.0.0.2
ansible_user: root
elasticsearch_node_master: false
elasticsearch_node_data: true
elasticsearch_node_ingest: false
elk3:
ansible_host: 10.0.0.3
ansible_user: root
elasticsearch_node_master: false
elasticsearch_node_data: false
elasticsearch_node_ingest: true
elk4:
ansible_host: 10.0.0.4
ansible_user: root
logstash:
children:
elk3:
elk4:
使用以下 inventory 设置,elk1 将是 master 节点,elk2 将是 data 节点,elk3 将是 ingest 节点,而 elk4 将同时是 data 和 ingest 节点。elk3 和 elk4 将成为托管 logstash 实例的节点。
升级集群¶
要升级整个 elastic search 集群中的软件包,请将软件包状态变量 elk_package_state 设置为 latest。
cd /opt/openstack-ansible-ops/elk_metrics_7x
ansible-playbook site.yml $USER_VARS -e 'elk_package_state="latest"'
强制 Elasticsearch 集群保留策略刷新¶
要强制集群保留策略刷新,请将 elastic_retention_refresh 设置为“yes”。当将 elastic_retention_refresh 设置为“yes”时,保留策略将在所有主机上强制刷新。仅当修改了现有集群上的 Elasticsearch 存储阵列时,才应使用此选项。如果 Elasticsearch 集群大小发生变化(添加或删除节点),则保留策略将在 playbook 执行时自动刷新。
cd /opt/openstack-ansible-ops/elk_metrics_7x
ansible-playbook site.yml $USER_VARS -e 'elastic_retention_refresh="yes"'
故障排除¶
如果一切都失败了,可以使用以下命令进行清理
openstack-ansible /opt/openstack-ansible-ops/elk_metrics_7x/site.yml -e 'elk_package_state="absent"' --tags package_install
openstack-ansible /opt/openstack-ansible/playbooks/lxc-containers-destroy.yml --limit elk_all
本地测试¶
要在本地环境中测试这些 playbook,您需要一台至少有 8GiB 内存和 40GiB 根存储的服务器。运行 m1.medium(openstack)flavor 大小通常足以使环境上线。
要运行本地功能测试,请从 tests 目录执行 run-tests.sh 脚本。这将创建一个 4 个节点 elasaticsearch 集群,1 个 kibana 节点和一个 Elasticsearch 协调进程,以及 1 个 APM 节点。Beats 将部署到环境,就像这是一个生产安装一样。
CLUSTERED=yes tests/run-tests.sh
完成测试构建后,集群将测试其布局并确保进程正常运行。集群日志可以在 /tmp/elk-metrics-7x-logs 中找到。
要在测试构建后重新运行 playbook,请获取 tests/manual-test.rc 文件并按照屏幕上的说明进行操作。
要清理测试环境并从裸服务器 slate 开始,可以使用 run-cleanup.sh 脚本。此脚本具有破坏性,并将清除本地测试环境中的所有 elk_metrics_7x 相关服务。
tests/run-cleanup.sh
启用 ELK 安全性¶
默认情况下,ELK 7 在未启用安全性的情况下部署。这意味着所有服务和用户交互都是未经验证的,并且通信是未加密的。
如果您希望启用安全功能,建议先部署一个禁用安全性的集群,然后再按照这些步骤操作。请注意,这是一个多阶段过程,并且需要不可避免的停机时间。
生成一个 Elastic 集群独有的证书颁发机构。确保您为证书包设置了密码。
生成 Elasticsearch 实例的密钥和证书。您可以使用所有主机的一个包,也可以根据需要使用唯一的包。同样,为这些设置密码。
安全地存储 CA 包,并配置以下 Elasticsearch Ansible 角色变量。对二进制证书包文件进行 base64 编码和解码可能很有用。 elastic_security_enabled: True elastic_security_cert_bundle: “cert-bundle-contents” elastic_security_cert_password: “cert-bundle-password”
停止所有 Elasticsearch 服务。
对所有集群节点运行“installElastic.yml” playbook。这将启用安全功能,但由于缺少身份验证凭据,将停止日志摄取和监控任务。
生成关键 ELK 服务的用户名和密码。安全地存储输出,并设置以下 Ansible 变量。系统用户的凭据会自动生成。
对于 Kibana 主机,设置以下变量:kibana_system_username kibana_system_password kibana_setup_username (*) kibana_setup_password (*)
对于 Logstash 主机,设置以下变量:logstash_system_username logstash_system_password logstash_internal_username (*) logstash_internal_password (*)
对于 Beats 主机,设置以下变量:beats_system_username beats_system_password beats_setup_username (*) beats_setup_password (*)
(*) 标有星号 (*) 的用户不会自动生成。这些必须在配置 Kibana 界面后手动设置。为了使 Kibana playbook 成功运行,可以最初使用 ‘elastic’ 超级用户作为 ‘kibana_setup_username/password’。
kibana_setup - 任何被分配了内置 kibana_admin 角色的用户 logstash_internal - 请参阅 https://elastic.ac.cn/guide/en/logstash/7.17/ls-security.html#ls-http-auth-basic beats_setup - 请参阅 https://elastic.ac.cn/guide/en/beats/filebeat/7.17/feature-roles.html 中的 setup 角色 - 此用户还必须被分配内置的 ingest_admin 角色
将 ‘kibana_object_encryption_key’ 设置为至少 32 字节的字符串。
对 Kibana 主机运行 ‘installKibana.yml’ playbook。这将完成它们的配置,并应允许您使用先前生成的 ‘elastic’ 用户登录到 Web 界面。
通过 Kibana 界面设置 Logstash、Beats 或其他需要的任何附加用户,并按照上述说明设置其变量。
通过运行 ‘installLogstash.yml’ 和 Beat 安装 playbook 来完成部署。
