[ English | 日本語 | Deutsch | Indonesia ]
网络故障排除¶
网络故障排除可能具有挑战性。网络问题可能在云的任何点引起问题。使用逻辑的故障排除过程可以帮助缓解问题并隔离网络问题的所在。本章旨在为您提供识别 nova-network 或 OpenStack Networking (neutron) 与 Linux Bridge 或 Open vSwitch 相关问题的必要信息。
使用 ip a 检查接口状态¶
在计算节点和运行 nova-network 的节点上,使用以下命令查看有关接口的信息,包括有关 IP、VLAN 以及您的接口是否启动的信息
# ip a
如果您遇到任何类型的网络困难,一个好的初始故障排除步骤是确保您的接口已启动。例如
$ ip a | grep state
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP
qlen 1000
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast
master br100 state UP qlen 1000
4: virbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN
5: br100: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP
您可以安全地忽略 virbr0 的状态,它是由 libvirt 创建的默认网桥,OpenStack 不使用。
可视化云中的 nova-network 流量¶
如果您已登录到实例并 ping 一个外部主机,例如 Google,则 ping 数据包将采用如图 图. Ping 数据包的路由 所示的路由。
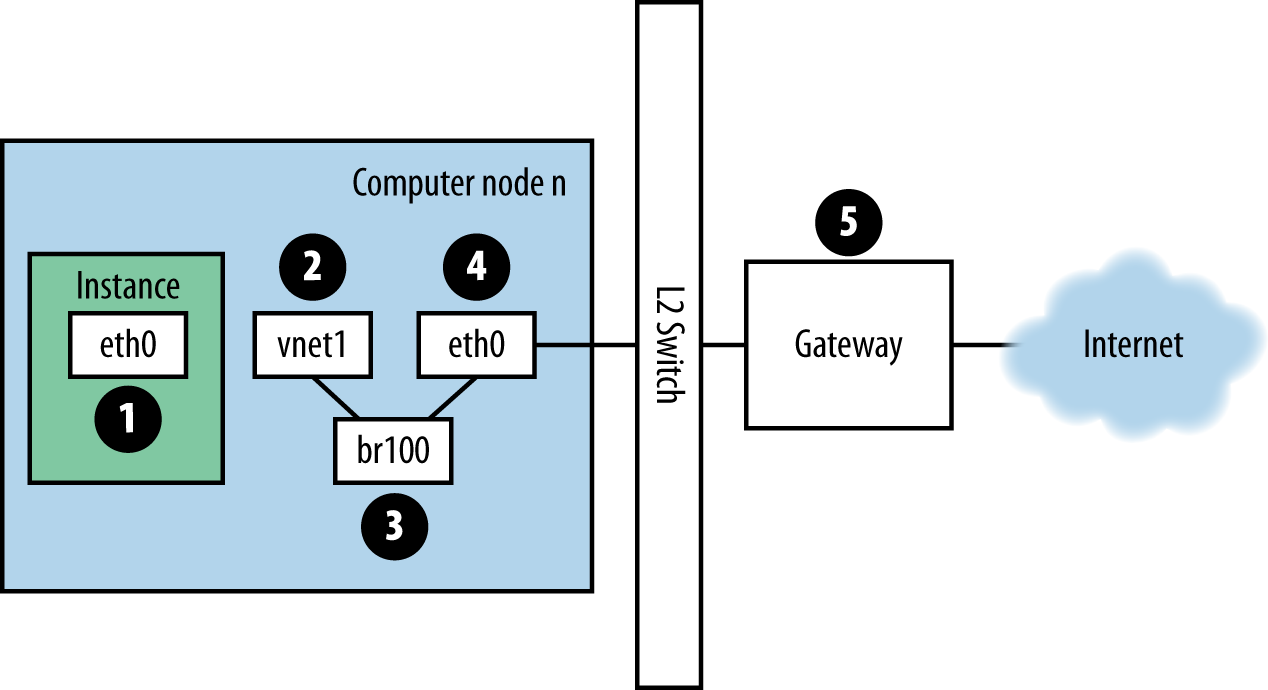
图. Ping 数据包的路由¶
实例生成数据包并将其放置在实例内的虚拟网络接口卡 (NIC) 上,例如
eth0。数据包传输到计算主机的虚拟 NIC,例如
vnet1。您可以通过查看/etc/libvirt/qemu/instance-xxxxxxxx.xml文件来确定正在使用的 vnet NIC。从 vnet NIC,数据包传输到计算节点上的网桥,例如
br100。如果您运行 FlatDHCPManager,则计算节点上有一个网桥。如果您运行 VlanManager,则每个 VLAN 存在一个网桥。
要查看数据包将使用哪个网桥,请运行以下命令
$ brctl show
查找 vnet NIC。您还可以参考
nova.conf并查找flat_interface_bridge选项。数据包传输到计算节点的main NIC。您也可以在 brctl 输出中看到此 NIC,或者可以通过参考
nova.conf中的flat_interface选项来找到它。数据包位于此 NIC 后,它将传输到计算节点的默认网关。此时,数据包很可能超出了您的控制范围。该图描绘了一个外部网关。但是,在具有多主机的默认配置中,计算节点是网关。
反转方向以查看 ping 响应的路径。从该路径可以看出,单个数据包跨越四个不同的 NIC 传输。如果这些 NIC 中的任何一个出现问题,则会发生网络问题。
可视化云中的 OpenStack Networking 服务流量¶
由于其可插拔的后端,OpenStack Networking 比 nova-network 具有更多的自由度。它可以配置为使用开源或供应商专有的插件来控制软件定义网络 (SDN) 硬件,或者使用 Linux 本机设施(如 Open vSwitch 或 Linux Bridge)的插件。
OpenStack 管理员指南 的网络章节展示了各种网络场景及其连接路径。本节的目的是为您提供故障排除所涉及的各种组件的工具,无论它们在您的环境中如何连接。
对于本示例,我们将使用 Open vSwitch (OVS) 后端。其他后端插件将具有非常不同的流量路径。根据 2016 年 4 月的 OpenStack 用户调查,OVS 是最常用的网络驱动程序。我们将依次描述每个步骤,并参考 图. Neutron 网络路径。
实例生成数据包并将其放置在实例内的虚拟 NIC 上,例如 eth0。
数据包传输到计算主机上的测试访问点 (TAP) 设备,例如 tap690466bc-92。您可以通过查看
/etc/libvirt/qemu/instance-xxxxxxxx.xml文件来确定正在使用的 TAP 设备。TAP 设备名称是通过使用端口 ID 的前 11 个字符(10 个十六进制数字加上包含的“-”)构建的,因此找到设备名称的另一种方法是使用 neutron 命令。这将返回一个以管道分隔的列表,其中第一项是端口 ID。例如,要获取与 IP 地址 10.0.0.10 关联的端口 ID,请执行此操作
# openstack port list | grep 10.0.0.10 | cut -d \| -f 2 ff387e54-9e54-442b-94a3-aa4481764f1d
取前 11 个字符,我们可以构造设备名称 tapff387e54-9e 从此输出。
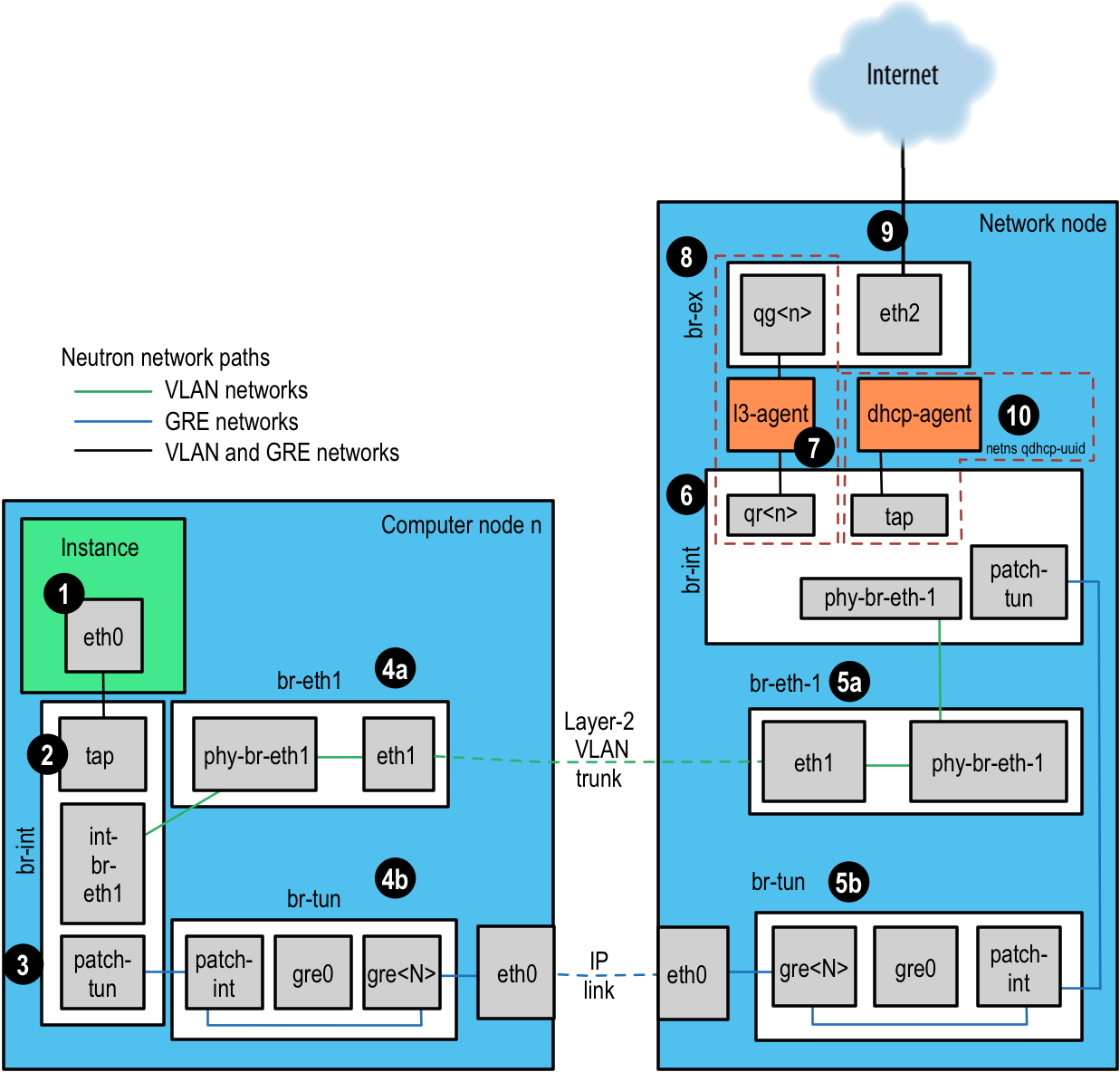
图. Neutron 网络路径¶
TAP 设备连接到集成网桥
br-int。此网桥连接所有实例 TAP 设备和系统上的任何其他网桥。在本例中,我们有int-br-eth1和patch-tun。int-br-eth1是 veth 对的一半,连接到网桥br-eth1,该网桥处理通过物理以太网设备eth1截断的 VLAN 网络。patch-tun是 Open vSwitch 内部端口,连接到br-tun网桥用于 GRE 网络。TAP 设备和 veth 设备是正常的 Linux 网络设备,可以使用常用的工具(如 ip 和 tcpdump)进行检查。Open vSwitch 内部设备,例如
patch-tun,仅在 Open vSwitch 环境内可见。如果您尝试运行 tcpdump -i patch-tun,它将引发错误,说明设备不存在。可以监视内部接口上的数据包,但这需要进行一些网络技巧。首先,您需要创建一个正常的 Linux 工具可以看到的虚拟网络设备。然后,您需要将其添加到包含您想要窥探的内部接口的网桥中。最后,您需要告诉 Open vSwitch 将所有流量镜像到或从内部端口到此虚拟端口。完成所有这些操作后,您就可以在虚拟接口上运行 tcpdump 并查看内部端口上的流量。
要从集成网桥 br-int 上的 patch-tun 内部接口捕获数据包
创建并启动虚拟接口
snooper0# ip link add name snooper0 type dummy # ip link set dev snooper0 up
将设备
snooper0添加到网桥br-int# ovs-vsctl add-port br-int snooper0
创建
patch-tun到snooper0的镜像(返回镜像端口的 UUID)# ovs-vsctl -- set Bridge br-int mirrors=@m -- --id=@snooper0 \ get Port snooper0 -- --id=@patch-tun get Port patch-tun \ -- --id=@m create Mirror name=mymirror select-dst-port=@patch-tun \ select-src-port=@patch-tun output-port=@snooper0 select_all=1
成功。现在,您可以通过运行 tcpdump -i snooper0 来查看
patch-tun上的流量。通过清除
br-int上的所有镜像并删除虚拟接口来清理# ovs-vsctl clear Bridge br-int mirrors # ovs-vsctl del-port br-int snooper0 # ip link delete dev snooper0
在集成网桥上,无论网络服务如何定义网络,网络都使用内部 VLAN 进行区分。这允许同一主机上的实例直接通信,而无需通过其余的虚拟或物理网络传输。这些内部 VLAN ID 基于它们在节点上创建的顺序,并且可能因节点而异。这些 ID 与网络定义中使用的分段 ID 以及物理线上的 ID 无关。
VLAN 标签在多个位置进行翻译,从外部标签定义在网络设置中,到内部标签。在
br-int上,来自int-br-eth1的传入数据包从外部标签转换为内部标签。其他翻译也发生在其他网桥上,将在这些部分中讨论。要使用 ovs-ofctl 命令发现正在为给定外部 VLAN 使用的内部 VLAN 标签
找到您感兴趣的网络的
provider:segmentation_id。这是网络服务返回的相同字段# neutron net-show --fields provider:segmentation_id <network name> +---------------------------+--------------------------------------+ | Field | Value | +---------------------------+--------------------------------------+ | provider:network_type | vlan | | provider:segmentation_id | 2113 | +---------------------------+--------------------------------------+
在
ovs-ofctl dump-flows br-int的输出中搜索provider:segmentation_id,在本例中为 2113# ovs-ofctl dump-flows br-int | grep vlan=2113 cookie=0x0, duration=173615.481s, table=0, n_packets=7676140, n_bytes=444818637, idle_age=0, hard_age=65534, priority=3, in_port=1,dl_vlan=2113 actions=mod_vlan_vid:7,NORMAL
在这里,您可以看到接收到的端口 ID 为 1 且 VLAN 标签为 2113 的数据包被修改为具有内部 VLAN 标签 7。深入挖掘,您可以确认端口 1 实际上是
int-br-eth1# ovs-ofctl show br-int OFPT_FEATURES_REPLY (xid=0x2): dpid:000022bc45e1914b n_tables:254, n_buffers:256 capabilities: FLOW_STATS TABLE_STATS PORT_STATS QUEUE_STATS ARP_MATCH_IP actions: OUTPUT SET_VLAN_VID SET_VLAN_PCP STRIP_VLAN SET_DL_SRC SET_DL_DST SET_NW_SRC SET_NW_DST SET_NW_TOS SET_TP_SRC SET_TP_DST ENQUEUE 1(int-br-eth1): addr:c2:72:74:7f:86:08 config: 0 state: 0 current: 10GB-FD COPPER speed: 10000 Mbps now, 0 Mbps max 2(patch-tun): addr:fa:24:73:75:ad:cd config: 0 state: 0 speed: 0 Mbps now, 0 Mbps max 3(tap9be586e6-79): addr:fe:16:3e:e6:98:56 config: 0 state: 0 current: 10MB-FD COPPER speed: 10 Mbps now, 0 Mbps max LOCAL(br-int): addr:22:bc:45:e1:91:4b config: 0 state: 0 speed: 0 Mbps now, 0 Mbps max OFPT_GET_CONFIG_REPLY (xid=0x4): frags=normal miss_send_len=0
下一步取决于虚拟网络是否配置为使用 802.1q VLAN 标签或 GRE
基于 VLAN 的网络通过 veth 接口
int-br-eth1退出集成网桥,并到达另一个网桥成员phy-br-eth1上的br-eth1。此接口上的数据包带有内部 VLAN 标签,并且以与上述过程相反的方式转换为外部标签# ovs-ofctl dump-flows br-eth1 | grep 2113 cookie=0x0, duration=184168.225s, table=0, n_packets=0, n_bytes=0, idle_age=65534, hard_age=65534, priority=4,in_port=1,dl_vlan=7 actions=mod_vlan_vid:2113,NORMAL
现在带有外部 VLAN 标签的数据包通过
eth1退出到物理网络。连接到此接口的 Layer2 交换机必须配置为接受使用 VLAN ID 的流量。此数据包的下一跳也必须位于同一 Layer2 网络上。基于 GRE 的网络通过
patch-tun传递到隧道网桥br-tun上的接口patch-int。此网桥还包含一个端口,用于每个 GRE 隧道对,因此一个用于网络中的每个计算节点和网络节点。端口按顺序命名,从gre-1开始。通过查看 Open vSwitch 状态可以匹配
gre-<n>接口到隧道端点# ovs-vsctl show | grep -A 3 -e Port\ \"gre- Port "gre-1" Interface "gre-1" type: gre options: {in_key=flow, local_ip="10.10.128.21", out_key=flow, remote_ip="10.10.128.16"}
在本例中,
gre-1是从 IP 10.10.128.21(应与此节点上的本地接口匹配)到远程侧 IP 10.10.128.16 的隧道。这些隧道使用主机的常规路由表来路由生成的 GRE 数据包,因此与 VLAN 封装不同,GRE 端点不必位于同一 Layer2 网络上。
br-tun上的所有接口都位于 Open vSwitch 内部。要监视它们上的流量,您需要按照上述为br-int中的patch-tun设置的镜像端口进行操作。所有 GRE 隧道到和从内部 VLAN 的转换都发生在此网桥上。
要使用 ovs-ofctl 命令发现正在为 GRE 隧道使用的内部 VLAN 标签
找到您感兴趣的网络的
provider:segmentation_id。这是用于基于 VLAN 网络的 VLAN ID 的相同字段# neutron net-show --fields provider:segmentation_id <network name> +--------------------------+-------+ | Field | Value | +--------------------------+-------+ | provider:network_type | gre | | provider:segmentation_id | 3 | +--------------------------+-------+
在
ovs-ofctl dump-flows br-tun的输出中搜索 0x<provider:segmentation_id>,在本例中为 0x3# ovs-ofctl dump-flows br-tun|grep 0x3 cookie=0x0, duration=380575.724s, table=2, n_packets=1800, n_bytes=286104, priority=1,tun_id=0x3 actions=mod_vlan_vid:1,resubmit(,10) cookie=0x0, duration=715.529s, table=20, n_packets=5, n_bytes=830, hard_timeout=300,priority=1, vlan_tci=0x0001/0x0fff,dl_dst=fa:16:3e:a6:48:24 actions=load:0->NXM_OF_VLAN_TCI[], load:0x3->NXM_NX_TUN_ID[],output:53 cookie=0x0, duration=193729.242s, table=21, n_packets=58761, n_bytes=2618498, dl_vlan=1 actions=strip_vlan,set_tunnel:0x3, output:4,output:58,output:56,output:11,output:12,output:47, output:13,output:48,output:49,output:44,output:43,output:45, output:46,output:30,output:31,output:29,output:28,output:26, output:27,output:24,output:25,output:32,output:19,output:21, output:59,output:60,output:57,output:6,output:5,output:20, output:18,output:17,output:16,output:15,output:14,output:7, output:9,output:8,output:53,output:10,output:3,output:2, output:38,output:37,output:39,output:40,output:34,output:23, output:36,output:35,output:22,output:42,output:41,output:54, output:52,output:51,output:50,output:55,output:33
在这里,您可以看到三个与此 GRE 隧道相关的流。第一个是将传入数据包从此隧道 ID 转换为内部 VLAN ID 1。第二个显示将数据包发送到目标 MAC 地址 fa:16:3e:a6:48:24 的单播流。第三个显示将内部 VLAN 表示形式转换为 GRE 隧道 ID 泛洪到所有输出端口。有关流描述的更多详细信息,请参阅
ovs-ofctl手册页。与前面的 VLAN 示例类似,可以通过检查ovs-ofctl show br-tun的输出将数字端口 ID 与其命名表示形式匹配。
然后,数据包在网络节点上接收。请注意,任何发送到 l3-agent 或 dhcp-agent 的流量仅在其网络命名空间内可见。即使是携带网络流量的接口,在这些命名空间之外监视任何接口也只会显示广播数据包,例如地址解析协议 (ARP),但发送到路由器或 DHCP 地址的单播流量将不会被看到。有关如何在此类命名空间中运行命令的详细信息,请参阅 处理网络命名空间。
或者,只要外部路由器位于同一 VLAN 上,就可以配置基于 VLAN 的网络以使用外部路由器而不是此处显示的 l3-agent
基于 VLAN 的网络作为带有标签的数据包在物理网络接口
eth1上接收。就像在计算节点上一样,此接口是网桥br-eth1的成员。基于 GRE 的网络将传递到隧道网桥
br-tun,其行为与计算节点上的 GRE 接口相同。
然后,来自任一输入的包通过集成网桥,就像在计算节点上一样。
然后,数据包到达 l3-agent。这实际上是路由器命名空间内的另一个 TAP 设备。路由器命名空间命名为
qrouter-<router-uuid>。在命名空间中运行 ip a 将显示 TAP 设备名称,qr-e6256f7d-31 在本例中# ip netns exec qrouter-e521f9d0-a1bd-4ff4-bc81-78a60dd88fe5 ip a | grep state 10: qr-e6256f7d-31: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN 11: qg-35916e1f-36: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UNKNOWN qlen 500 28: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
l3-agent 路由器命名空间中的
qg-<n>接口通过外部网桥br-ex上的设备eth2将数据包发送到其下一跳。此网桥的构建方式与br-eth1类似,并且可以以相同的方式进行检查。这个外部桥接还包括一个物理网络接口,例如本例中的
eth2,最终将数据包发送到外部网络,目标是外部路由器或目的地。在 OpenStack 网络上运行的 DHCP 代理在与 l3 代理类似的命名空间中运行。DHCP 命名空间命名为
qdhcp-<uuid>,并在集成桥接上有一个 TAP 设备。调试 DHCP 问题通常涉及在那个网络命名空间内工作。
查找路径中的故障点¶
使用 ping 快速找到网络路径中存在故障的位置。在实例中,首先查看是否可以 ping 一个外部主机,例如 google.com。如果可以,那么应该没有网络问题。
如果不能,尝试 ping 托管实例的计算节点的 IP 地址。如果可以 ping 到这个 IP,那么问题就在计算节点及其网关之间。
如果无法 ping 到计算节点的 IP 地址,那么问题就在实例和计算节点之间。这包括连接计算节点的主 NIC 与实例的 vnet NIC 的桥接。
最后一个测试是启动第二个实例,看看这两个实例是否可以 ping 通彼此。如果可以,问题可能与计算节点上的防火墙有关。
tcpdump¶
一种很棒但非常深入的网络问题故障排除方法是使用 tcpdump。我们建议在网络路径的几个点使用 tcpdump,以确定问题可能出在哪里。如果您更喜欢使用 GUI,无论是实时使用还是使用 tcpdump 捕获,请查看 Wireshark。
例如,运行以下命令
# tcpdump -i any -n -v 'icmp[icmptype] = icmp-echoreply or icmp[icmptype] = icmp-echo'
在以下区域的命令行上运行
云之外的外部服务器
一个计算节点
在该计算节点上运行的实例
在本例中,这些位置具有以下 IP 地址
Instance
10.0.2.24
203.0.113.30
Compute Node
10.0.0.42
203.0.113.34
External Server
1.2.3.4
接下来,打开一个到实例的新 shell,然后 ping 运行 tcpdump 的外部主机。如果到外部服务器和返回的网络路径完全正常,您会看到如下内容
在外部服务器上
12:51:42.020227 IP (tos 0x0, ttl 61, id 0, offset 0, flags [DF],
proto ICMP (1), length 84)
203.0.113.30 > 1.2.3.4: ICMP echo request, id 24895, seq 1, length 64
12:51:42.020255 IP (tos 0x0, ttl 64, id 8137, offset 0, flags [none],
proto ICMP (1), length 84)
1.2.3.4 > 203.0.113.30: ICMP echo reply, id 24895, seq 1,
length 64
在计算节点上
12:51:42.019519 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF],
proto ICMP (1), length 84)
10.0.2.24 > 1.2.3.4: ICMP echo request, id 24895, seq 1, length 64
12:51:42.019519 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF],
proto ICMP (1), length 84)
10.0.2.24 > 1.2.3.4: ICMP echo request, id 24895, seq 1, length 64
12:51:42.019545 IP (tos 0x0, ttl 63, id 0, offset 0, flags [DF],
proto ICMP (1), length 84)
203.0.113.30 > 1.2.3.4: ICMP echo request, id 24895, seq 1, length 64
12:51:42.019780 IP (tos 0x0, ttl 62, id 8137, offset 0, flags [none],
proto ICMP (1), length 84)
1.2.3.4 > 203.0.113.30: ICMP echo reply, id 24895, seq 1, length 64
12:51:42.019801 IP (tos 0x0, ttl 61, id 8137, offset 0, flags [none],
proto ICMP (1), length 84)
1.2.3.4 > 10.0.2.24: ICMP echo reply, id 24895, seq 1, length 64
12:51:42.019807 IP (tos 0x0, ttl 61, id 8137, offset 0, flags [none],
proto ICMP (1), length 84)
1.2.3.4 > 10.0.2.24: ICMP echo reply, id 24895, seq 1, length 64
在实例上
12:51:42.020974 IP (tos 0x0, ttl 61, id 8137, offset 0, flags [none],
proto ICMP (1), length 84)
1.2.3.4 > 10.0.2.24: ICMP echo reply, id 24895, seq 1, length 64
这里,外部服务器收到了 ping 请求并发送了 ping 响应。在计算节点上,您可以看到 ping 和 ping 响应都成功通过。您可能还会看到计算节点上的重复数据包,如上所示,因为 tcpdump 在桥接和出站接口上都捕获了数据包。
iptables¶
通过 nova-network 或 neutron,OpenStack Compute 会自动管理 iptables,包括转发到实例和从实例转发的数据包,转发浮动 IP 流量以及管理安全组规则。除了管理规则之外,如果支持,还会在规则中插入注释以帮助指示规则的目的。
以下注释会根据需要添加到规则集中
对出站流量执行源 NAT。
用于未匹配流量的默认丢弃规则。
将来自 VM 接口的流量定向到安全组链。
跳转到 VM 特定链。
将来自 VM 的传入流量定向到安全组链。
允许来自定义的 IP/MAC 对的流量。
丢弃没有 IP/MAC 允许规则的流量。
允许 DHCP 客户端流量。
防止 VM 进行 DHCP 欺骗。
将未匹配的流量发送到回退链。
丢弃与状态无关的数据包。
将与已知会话相关联的数据包定向到 RETURN 链。
允许 IPv6 ICMP 流量以允许 RA 数据包。
运行以下命令以查看当前的 iptables 配置
# iptables-save
注意
如果您修改了配置,下次重新启动 nova-network 或 neutron-server 时,它将恢复。您必须使用 OpenStack 来管理 iptables。
nova-network 的数据库中的网络配置¶
使用 nova-network 时,nova 数据库表包含几个包含网络信息的表
fixed_ips包含添加到 Compute 的子网的每个可能的 IP 地址。此表通过
fixed_ips.instance_uuid列与instances表相关联。floating_ips包含添加到 Compute 的每个浮动 IP 地址。此表通过
floating_ips.fixed_ip_id列与fixed_ips表相关联。instances并非完全网络相关,但它包含有关使用
fixed_ip和可选floating_ip的实例的信息。
从这些表中可以看出,浮动 IP 在技术上从不直接与实例相关联;它必须始终通过固定 IP。
手动取消关联浮动 IP¶
有时,实例被终止,但浮动 IP 未正确从该实例取消关联。由于数据库处于不一致状态,通常用于取消关联 IP 的工具不再起作用。要解决此问题,您必须手动更新数据库。
首先,找到问题的实例的 UUID
mysql> select uuid from instances where hostname = 'hostname';
接下来,找到该 UUID 的固定 IP 条目
mysql> select * from fixed_ips where instance_uuid = '<uuid>';
现在,您可以获取相关的浮动 IP 条目
mysql> select * from floating_ips where fixed_ip_id = '<fixed_ip_id>';
最后,您可以取消关联浮动 IP
mysql> update floating_ips set fixed_ip_id = NULL, host = NULL where
fixed_ip_id = '<fixed_ip_id>';
您可以选择性地将 IP 从用户的池中释放
mysql> update floating_ips set project_id = NULL where
fixed_ip_id = '<fixed_ip_id>';
使用 nova-network 调试 DHCP 问题¶
一个常见的网络问题是实例成功启动,但无法访问,因为它未能从 dnsmasq 获取 IP 地址,dnsmasq 是由 nova-network 服务启动的 DHCP 服务器。
识别此问题的最简单方法是查看实例的控制台输出。如果 DHCP 失败,您可以执行以下操作来检索控制台日志
$ openstack console log show <instance name or uuid>
如果实例未能通过 DHCP 获取 IP,控制台中应该会出现一些消息。例如,对于 Cirros 镜像,您会看到如下输出
udhcpc (v1.17.2) started
Sending discover...
Sending discover...
Sending discover...
No lease, forking to background
starting DHCP forEthernet interface eth0 [ [1;32mOK[0;39m ]
cloud-setup: checking http://169.254.169.254/2009-04-04/meta-data/instance-id
wget: can't connect to remote host (169.254.169.254): Network is
unreachable
在确定实例已正确启动后,任务是找出故障所在。
DHCP 问题可能是由行为不当的 dnsmasq 进程引起的。首先,通过检查日志进行调试,然后仅重新启动该项目(租户)的 dnsmasq 进程。在 VLAN 模式下,每个租户都有一个 dnsmasq 进程。重新启动有针对性的 dnsmasq 进程后,排除 dnsmasq 原因的最简单方法是杀死机器上的所有 dnsmasq 进程并重新启动 nova-network。作为最后的手段,以 root 身份执行此操作
# killall dnsmasq
# restart nova-network
注意
在 RHEL/CentOS/Fedora 上使用 openstack-nova-network,但在 Ubuntu/Debian 上使用 nova-network。
在重新启动 nova-network 几分钟后,您应该会看到新的 dnsmasq 进程正在运行
# ps aux | grep dnsmasq
nobody 3735 0.0 0.0 27540 1044 ? S 15:40 0:00 /usr/sbin/dnsmasq --strict-order
--bind-interfaces --conf-file=
--domain=novalocal --pid-file=/var/lib/nova/networks/nova-br100.pid
--listen-address=192.168.100.1 --except-interface=lo
--dhcp-range=set:'novanetwork',192.168.100.2,static,120s
--dhcp-lease-max=256
--dhcp-hostsfile=/var/lib/nova/networks/nova-br100.conf
--dhcp-script=/usr/bin/nova-dhcpbridge --leasefile-ro
root 3736 0.0 0.0 27512 444 ? S 15:40 0:00 /usr/sbin/dnsmasq --strict-order
--bind-interfaces --conf-file=
--domain=novalocal --pid-file=/var/lib/nova/networks/nova-br100.pid
--listen-address=192.168.100.1 --except-interface=lo
--dhcp-range=set:'novanetwork',192.168.100.2,static,120s
--dhcp-lease-max=256
--dhcp-hostsfile=/var/lib/nova/networks/nova-br100.conf
--dhcp-script=/usr/bin/nova-dhcpbridge --leasefile-ro
如果您的实例仍然无法获取 IP 地址,下一步是检查 dnsmasq 是否看到来自实例的 DHCP 请求。在运行 dnsmasq 进程的机器上,即在多主机模式下为计算主机,查看 /var/log/syslog 以查看 dnsmasq 输出。如果 dnsmasq 正确看到请求并分配 IP,输出如下所示
Feb 27 22:01:36 mynode dnsmasq-dhcp[2438]: DHCPDISCOVER(br100) fa:16:3e:56:0b:6f
Feb 27 22:01:36 mynode dnsmasq-dhcp[2438]: DHCPOFFER(br100) 192.168.100.3
fa:16:3e:56:0b:6f
Feb 27 22:01:36 mynode dnsmasq-dhcp[2438]: DHCPREQUEST(br100) 192.168.100.3
fa:16:3e:56:0b:6f
Feb 27 22:01:36 mynode dnsmasq-dhcp[2438]: DHCPACK(br100) 192.168.100.3
fa:16:3e:56:0b:6f test
如果您看不到 DHCPDISCOVER,则数据包从实例到运行 dnsmasq 的机器之间存在问题。如果您看到所有上述输出,但您的实例仍然无法获取 IP 地址,那么数据包能够从实例到达运行 dnsmasq 的主机,但无法完成返回行程。
您可能还会看到如下消息
Feb 27 22:01:36 mynode dnsmasq-dhcp[25435]: DHCPDISCOVER(br100)
fa:16:3e:78:44:84 no address available
这可能是 dnsmasq 和/或 nova-network 相关问题。(对于前面的示例,问题恰恰是 dnsmasq 没有更多的 IP 地址可以分配,因为 OpenStack Compute 数据库中没有更多的固定 IP 可用。)
如果 dnsmasq 日志消息看起来可疑,请查看 dnsmasq 进程的命令行参数,以查看它们是否正确
$ ps aux | grep dnsmasq
输出如下所示
108 1695 0.0 0.0 25972 1000 ? S Feb26 0:00 /usr/sbin/dnsmasq
-u libvirt-dnsmasq
--strict-order --bind-interfaces
--pid-file=/var/run/libvirt/network/default.pid --conf-file=
--except-interface lo --listen-address 192.168.122.1
--dhcp-range 192.168.122.2,192.168.122.254
--dhcp-leasefile=/var/lib/libvirt/dnsmasq/default.leases
--dhcp-lease-max=253 --dhcp-no-override
nobody 2438 0.0 0.0 27540 1096 ? S Feb26 0:00 /usr/sbin/dnsmasq
--strict-order --bind-interfaces --conf-file=
--domain=novalocal --pid-file=/var/lib/nova/networks/nova-br100.pid
--listen-address=192.168.100.1
--except-interface=lo
--dhcp-range=set:'novanetwork',192.168.100.2,static,120s
--dhcp-lease-max=256
--dhcp-hostsfile=/var/lib/nova/networks/nova-br100.conf
--dhcp-script=/usr/bin/nova-dhcpbridge --leasefile-ro
root 2439 0.0 0.0 27512 472 ? S Feb26 0:00 /usr/sbin/dnsmasq --strict-order
--bind-interfaces --conf-file=
--domain=novalocal --pid-file=/var/lib/nova/networks/nova-br100.pid
--listen-address=192.168.100.1
--except-interface=lo
--dhcp-range=set:'novanetwork',192.168.100.2,static,120s
--dhcp-lease-max=256
--dhcp-hostsfile=/var/lib/nova/networks/nova-br100.conf
--dhcp-script=/usr/bin/nova-dhcpbridge --leasefile-ro
输出显示三个不同的 dnsmasq 进程。属于 libvirt 的 dnsmasq 进程具有 DHCP 子网范围 192.168.122.0,可以忽略。另外两个 dnsmasq 进程属于 nova-network。这两个进程实际上是相关的——一个只是另一个进程的父进程。dnsmasq 进程的参数应与您使用 nova-network 配置的详细信息相对应。
如果问题似乎与 dnsmasq 本身无关,那么此时使用 tcpdump 监听接口,以确定数据包丢失的位置。
DHCP 流量使用 UDP。客户端从端口 68 发送到服务器上的端口 67。尝试启动新实例,然后系统地监听 NIC,直到找到看不到流量的 NIC。要使用 tcpdump 监听 br100 上的端口 67 和 68,您可以执行
# tcpdump -i br100 -n port 67 or port 68
您应该使用命令(如 ip a 和 brctl show)对接口进行健全性检查,以确保接口已启动并配置为您认为的方式。
调试 DNS 问题¶
如果您可以使用 SSH 登录到实例,但需要很长时间(大约一分钟)才能获得提示,那么您可能存在 DNS 问题。DNS 问题可能导致此问题的原因是 SSH 服务器会对您连接的 IP 地址执行反向 DNS 查找。如果实例上的 DNS 查找不起作用,那么您必须等待 DNS 反向查找超时才能完成 SSH 登录过程。
在调试 DNS 问题时,首先确保运行该实例的 dnsmasq 进程的主机能够正确解析。如果主机无法解析,那么实例也无法解析。
检查 DNS 是否正常工作的一种快速方法是在实例内使用 host 命令解析主机名。如果 DNS 正常工作,您应该会看到
$ host openstack.org
openstack.org has address 174.143.194.225
openstack.org mail is handled by 10 mx1.emailsrvr.com.
openstack.org mail is handled by 20 mx2.emailsrvr.com.
如果您正在运行 Cirros 镜像,它没有安装“host”程序,在这种情况下,您可以使用 ping 尝试通过主机名访问机器,以查看它是否可以解析。如果 DNS 正常工作,ping 的第一行将是
$ ping openstack.org
PING openstack.org (174.143.194.225): 56 data bytes
如果实例无法解析主机名,则存在 DNS 问题。例如
$ ping openstack.org
ping: bad address 'openstack.org'
在 OpenStack 云中,dnsmasq 进程充当实例的 DNS 服务器,以及充当 DHCP 服务器。行为不当的 dnsmasq 进程可能是实例内部 DNS 相关问题的根源。如前一节所述,排除行为不当的 dnsmasq 进程的最简单方法是杀死机器上的所有 dnsmasq 进程并重新启动 nova-network。但是,请注意,此命令会影响在此节点上运行实例的每个人,包括尚未遇到问题的租户。作为最后的手段,以 root 身份执行
# killall dnsmasq
# restart nova-network
在 dnsmasq 进程重新启动后,检查 DNS 是否正常工作。
如果重新启动 dnsmasq 进程无法解决问题,您可能需要使用 tcpdump 查看数据包,以跟踪故障所在。DNS 服务器监听 UDP 端口 53。您应该在计算节点的桥接(例如,br100)上看到 DNS 请求。假设您使用 tcpdump 在计算节点上开始监听
# tcpdump -i br100 -n -v udp port 53
tcpdump: listening on br100, link-type EN10MB (Ethernet), capture size 65535 bytes
然后,如果您使用 SSH 登录到实例并尝试 ping openstack.org,您应该会看到如下内容
16:36:18.807518 IP (tos 0x0, ttl 64, id 56057, offset 0, flags [DF],
proto UDP (17), length 59)
192.168.100.4.54244 > 192.168.100.1.53: 2+ A? openstack.org. (31)
16:36:18.808285 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF],
proto UDP (17), length 75)
192.168.100.1.53 > 192.168.100.4.54244: 2 1/0/0 openstack.org. A
174.143.194.225 (47)
排查 Open vSwitch¶
在前面的 OpenStack Networking 示例中使用的 Open vSwitch 是一个功能齐全的多层虚拟交换机,采用开源 Apache 2.0 许可。可以在 项目网站 上找到完整的文档。在实践中,鉴于上述配置,最常见的问题是确保所需的桥接(br-int、br-tun 和 br-ex)存在并且具有正确连接的端口。
Open vSwitch 驱动程序应该并且通常会自动管理此操作,但了解如何使用 ovs-vsctl 命令手动执行此操作很有用。此命令具有比我们在此处使用的更多子命令;有关完整列表,请参阅 man 页面或使用 ovs-vsctl --help。
要列出系统上的桥接,请使用 ovs-vsctl list-br。此示例显示一个计算节点具有内部桥接和一个隧道桥接。VLAN 网络通过 eth1 网络接口进行干路传输
# ovs-vsctl list-br
br-int
br-tun
eth1-br
从物理接口向内工作,我们可以看到端口和桥接的链。首先,桥接 eth1-br,它包含物理网络接口 eth1 和虚拟接口 phy-eth1-br
# ovs-vsctl list-ports eth1-br
eth1
phy-eth1-br
接下来,内部桥接器 br-int 包含 int-eth1-br,它与 phy-eth1-br 配对以连接到物理网络,如前一个桥接器 patch-tun 所示,该桥接器用于连接到 GRE 隧道桥接器和连接到当前在系统上运行的实例的 TAP 设备
# ovs-vsctl list-ports br-int
int-eth1-br
patch-tun
tap2d782834-d1
tap690466bc-92
tap8a864970-2d
隧道桥接器 br-tun 包含 patch-int 接口和通过 GRE 连接到每个对等体的 gre-<N> 接口,每个计算和网络节点在您的集群中都有一个
# ovs-vsctl list-ports br-tun
patch-int
gre-1
.
.
.
gre-<N>
如果缺少或不正确任何这些链路,则表明存在配置错误。可以使用 ovs-vsctl add-br 添加桥接器,并可以使用 ovs-vsctl add-port 将端口添加到桥接器。虽然手动运行这些命令可以用于调试,但必须将您打算保留的手动更改反映回您的配置文件。
处理网络命名空间¶
Linux 网络命名空间是网络服务用来支持具有重叠 IP 地址范围的多个隔离的第二层网络的一种内核特性。该支持可能会被禁用,但默认情况下是启用的。如果它在您的环境中启用,您的网络节点将在隔离的命名空间中运行它们的 dhcp-agent 和 l3-agent。这些接口上的网络接口和流量在默认命名空间中将不可见。
要查看您是否正在使用命名空间,请运行 ip netns
# ip netns
qdhcp-e521f9d0-a1bd-4ff4-bc81-78a60dd88fe5
qdhcp-a4d00c60-f005-400e-a24c-1bf8b8308f98
qdhcp-fe178706-9942-4600-9224-b2ae7c61db71
qdhcp-0a1d0a27-cffa-4de3-92c5-9d3fd3f2e74d
qrouter-8a4ce760-ab55-4f2f-8ec5-a2e858ce0d39
L3-agent 路由器命名空间命名为 qrouter-<router_uuid>,dhcp-agent 命名空间命名为 qdhcp-<net_uuid>。此输出显示一个网络节点,其中有四个网络正在运行 dhcp-agent,其中一个也在运行 l3-agent 路由器。了解您需要在哪一个网络中工作非常重要。可以通过使用管理凭据运行 openstack network list 来获取现有网络及其 UUID 的列表。
确定您需要使用的命名空间后,可以通过在命令前加上 ip netns exec <namespace> 来使用前面提到的任何调试工具。例如,要查看上述第一个 qdhcp 命名空间中存在的网络接口,请执行以下操作
# ip netns exec qdhcp-e521f9d0-a1bd-4ff4-bc81-78a60dd88fe5 ip a
10: tape6256f7d-31: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN
link/ether fa:16:3e:aa:f7:a1 brd ff:ff:ff:ff:ff:ff
inet 10.0.1.100/24 brd 10.0.1.255 scope global tape6256f7d-31
inet 169.254.169.254/16 brd 169.254.255.255 scope global tape6256f7d-31
inet6 fe80::f816:3eff:feaa:f7a1/64 scope link
valid_lft forever preferred_lft forever
28: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
从这里可以看出,该网络上的 DHCP 服务器正在使用 tape6256f7d-31 设备,并且具有 IP 地址 10.0.1.100。看到地址 169.254.169.254,您还可以看到 dhcp-agent 正在运行 metadata-proxy 服务。可以以相同的方式运行之前在本章中提到的任何命令。也可以运行 shell,例如 bash,并在命名空间内进行交互式会话。在后一种情况下,退出 shell 会将您返回到顶级默认命名空间。
将丢失的 IPv4 地址重新分配给项目¶
使用管理员凭据,确认丢失的 IP 地址仍然可用
# openstack server list --all-project | grep 'IP-ADDRESS'
创建端口
$ openstack port create --network NETWORK_ID PORT_NAME
使用 IPv4 地址更新新端口
# openstack subnet list # neutron port-update PORT_NAME --request-format=json --fixed-ips \ type=dict list=true subnet_id=NETWORK_ID_IPv4_SUBNET_ID \ ip_address=IP_ADDRESS subnet_id=NETWORK_ID_IPv6_SUBNET_ID # openstack port show PORT-NAME
用于自动 neutron 诊断的工具¶
easyOVS 是在操作您的 OpenvSwitch 桥接器和 iptables 在您的 OpenStack 平台上时的一个有用工具。它会自动将虚拟端口与 VM MAC/IP、VLAN 标签和命名空间信息以及 VM 的 iptables 规则关联起来。
Don 是另一个方便的网络分析和诊断系统,它为验证和诊断 OVS 提供的网络功能提供了一个完全自动化的服务。
此外,您可以参考 neutron client 以获取更多选项。
