Jobs¶
概述¶
Jobs 和 jobboards 是 TaskFlow 提供的一种新颖概念,用于允许工作流在有能力的拥有者(这些拥有者通常会使用 engines 来完成工作流)之间自动转移所有权。它们提供了必要的语义,能够以原子方式将作业从生产者可靠且容错地转移到消费者。它们借鉴了物理世界中发布和获取工作的方式(通常报纸或在线网站上的招聘信息起着类似的作用)。
简而言之: 它类似于队列,但消费者在声明时会锁定队列中的项目,并且仅在完成工作后才将其从队列中移除。如果消费者失败,锁将自动释放,并且该项目将返回队列以供进一步消费。
注意
有关更多信息,请访问 范式转变 页面以获取更多详细信息。
定义¶
高级架构¶
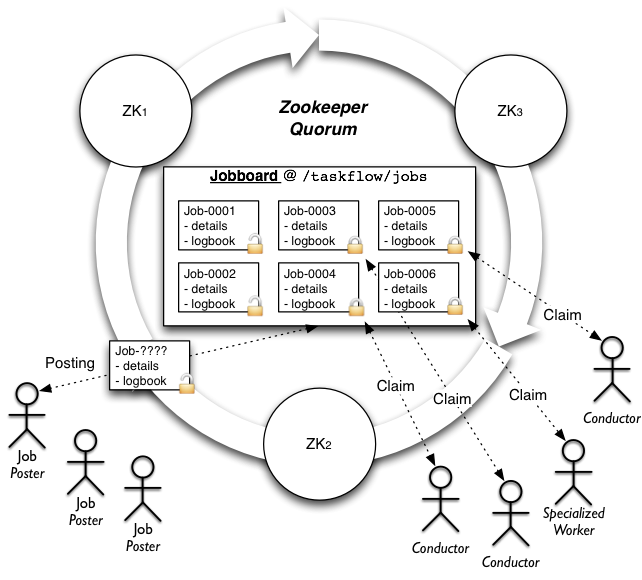
注意: 此图显示了高级图(并且此文档的其他部分也引用了它)的 zookeeper 实现(其他实现通常具有不同的架构)。¶
特性¶
高可用性
原子转移和单一所有权
确保同一时间只有一个工作流由单个所有者管理(包括当工作流转移到恢复其他失败所有者工作的拥有者时)。这避免了争用,并确保工作流由一个且只有一个实体管理。
注意: 这并不意味着所有者需要自己运行工作流,而是说该所有者可以使用 engine 以分布式方式运行工作,以确保工作流的推进。
工作流构建和执行的分离
可以使用 logbooks 创建作业,logbooks 包含一个关于实体(例如 API 服务器)要完成的工作的规范。然后,该作业可以由监视该 jobboard 的实体(不一定是 API 服务器本身)完成。这在工作形成和工作完成之间创建了断开连接,这对于横向扩展很有用。
异步完成
例如,当 API 服务器将作业发布到 jobboard 以供完成时,该 API 服务器可以向调用 API 服务的用户返回一个跟踪标识符。用户可以使用此跟踪标识符来轮询状态(类似于 FedEx 或 UPS 创建的运输跟踪标识符)。
用法¶
所有 jobboards 都是实现相同接口的类,当然也可以像在 Python 中导入和创建任何其他类一样导入和创建它们。但是,创建 jobboards 的更简单(推荐)方法是使用 fetch() 函数,该函数使用 entrypoints(内部使用 stevedore)来获取和配置后端。
使用此函数,典型的 jobboard 创建(以及发布作业的示例)可能如下所示
from taskflow.persistence import backends as persistence_backends
from taskflow.jobs import backends as job_backends
...
persistence = persistence_backends.fetch({
"connection': "mysql",
"user": ...,
"password": ...,
})
book = make_and_save_logbook(persistence)
board = job_backends.fetch('my-board', {
"board": "zookeeper",
}, persistence=persistence)
job = board.post("my-first-job", book)
...
类似地,通过创建 jobboard 并使用迭代功能来查找和声明作业(并最终消费它们)来消费作业。典型的 jobboard 用法(用于消费和工作完成)可能如下所示
import time
from taskflow import exceptions as exc
from taskflow.persistence import backends as persistence_backends
from taskflow.jobs import backends as job_backends
...
my_name = 'worker-1'
coffee_break_time = 60
persistence = persistence_backends.fetch({
"connection': "mysql",
"user": ...,
"password": ...,
})
board = job_backends.fetch('my-board', {
"board": "zookeeper",
}, persistence=persistence)
while True:
my_job = None
for job in board.iterjobs(only_unclaimed=True):
try:
board.claim(job, my_name)
except exc.UnclaimableJob:
pass
else:
my_job = job
break
if my_job is not None:
try:
perform_job(my_job)
except Exception:
LOG.exception("I failed performing job: %s", my_job)
board.abandon(my_job, my_name)
else:
# I finished it, now cleanup.
board.consume(my_job)
persistence.get_connection().destroy_logbook(my_job.book.uuid)
time.sleep(coffee_break_time)
...
有几种方法可以在 flow 中提供参数。第一种选择是在 logbook 中的 flowdetail 对象中添加一个 store。
您也可以在将作业发布到 job board 时在 job 本身中提供一个 store。如果找到这两个 store 值,它们将被组合,job store 将覆盖 logbook store。
from oslo_utils import uuidutils
from taskflow import engines
from taskflow.persistence import backends as persistence_backends
from taskflow.persistence import models
from taskflow.jobs import backends as job_backends
...
persistence = persistence_backends.fetch({
"connection': "mysql",
"user": ...,
"password": ...,
})
board = job_backends.fetch('my-board', {
"board": "zookeeper",
}, persistence=persistence)
book = models.LogBook('my-book', uuidutils.generate_uuid())
flow_detail = models.FlowDetail('my-job', uuidutils.generate_uuid())
book.add(flow_detail)
connection = persistence.get_connection()
connection.save_logbook(book)
flow_detail.meta['store'] = {'a': 1, 'c': 3}
job_details = {
"flow_uuid": flow_detail.uuid,
"store": {'a': 2, 'b': 1}
}
engines.save_factory_details(flow_detail, flow_factory,
factory_args=[],
factory_kwargs={},
backend=persistence)
jobboard = get_jobboard(zk_client)
jobboard.connect()
job = jobboard.post('my-job', book=book, details=job_details)
# the flow global parameters are now the combined store values
# {'a': 2, 'b': 1', 'c': 3}
...
类型¶
Zookeeper¶
Board 类型: 'zookeeper'
使用 zookeeper 通过使用 zookeeper 目录、短暂节点、非短暂节点和监视来提供 jobboard 功能和语义。
其他关键字参数
client: 提供kazoo.client.KazooClient-like 接口的类;它将用于 zookeeper 交互,在 jobboard 实例之间共享客户端可能会提供更好的可扩展性,并有助于避免创建太多与一组 zookeeper 服务器的开放连接。persistence: 提供 persistence 后端接口的类;它将用于加载作业 logbooks 以在运行时使用或在声明作业进行检查之前使用。
其他配置参数
path: 存储作业信息的 zookeeper 根路径(默认值为/taskflow/jobs)hosts: 要连接的 zookeeper 主机列表(默认值为localhost:2181);仅当未提供客户端时才使用。timeout: 执行 zookeeper 操作时使用的超时时间;仅当未提供客户端时才使用。handler: 提供kazoo.handlers-like 接口的类;它将由 kazoo 内部用于执行异步操作,当您的程序使用 eventlet 并且您希望指示 kazoo 使用与 eventlet 兼容的处理程序时,这很有用。
注意
有关实现细节,请参阅 ZookeeperJobBoard。
Redis¶
Board 类型: 'redis'
使用 redis 通过使用 redis 哈希数据结构和单个作业所有权键(可以配置在给定时间后过期)来提供 jobboard 功能和语义。
注意
有关实现细节,请参阅 RedisJobBoard。
Etcd¶
Board 类型: 'etcd'
使用 etcd 通过使用 Etcd 键值数据结构和单个作业所有权键(可以配置在给定时间后过期)来提供 jobboard 功能。
其他关键字参数
persistence: 提供 persistence 后端接口的类;它将用于加载作业 logbooks 以在运行时使用或在声明作业进行检查之前使用。
其他配置参数
path: 存储作业信息的 Etcd 路径(默认值为jobboard)host: 要连接的 Etcd 主机(默认值为localhost)port: Etcd 服务器的端口(默认值为2379)api_path: Etcd API 端点的路径protocol: 用于与服务器通信的协议(默认值为http,选项为http或https)ca_cert、cert_key和cert_cert: 传递给 Etcd3gw 的证书信息,用于https通信timeout: 执行 Etcd 操作时使用的超时时间ttl: 声明作业时的默认生存时间(默认值为None)
注意
有关实现细节,请参阅 EtcdJobBoard。
注意事项¶
在使用 jobboard 时,应使用一些使用注意事项,以确保其以安全可靠的方式使用。最终我们希望使这些成为非问题,但现在它们值得一提。
双引擎作业¶
是什么: 由于 atoms 和 engines 当前不可抢占,因此我们无法强制 engine(或它用于运行的线程/远程工作者……)停止处理 atom(强制代码停止而不经其同意通常是坏行为),如果它已经开始处理 atom。这可能会导致问题,因为 engine 可以注意到它不再拥有声明的时间点是在任何 state 更改发生时(例如,过渡到新的 atom 或记录结果),此时注意到声明丢失后,engine 可以立即停止进行进一步的工作。造成的影响是,当声明丢失时,另一个 engine 可以立即尝试获取先前丢失的声明,并且它可能会开始处理另一个 engine 可能仍在执行的未完成任务(因为该 engine 尚未意识到它丢失了声明)。
简而言之: 不可抢占,在下一个状态更改后才能意识到失去声明的事实,另一个 engine 可能会在此期间获取声明,因此两者都在处理作业。
通过以下方式缓解
确保您的 atoms 是幂等的,这将导致可能正在执行相同 atom 的 engine 能够继续执行而不会造成任何冲突/问题(幂等性保证这一点)。
在声明先前声明过的作业之前,强制执行一项策略,该策略发生在作业的工作流程开始之前(可能在 engine 开始作业的工作之前),以确保任何先前的工作都已回滚后再继续前进。例如
回滚最后完成的 atom/atom 集。
回滚发生的最后状态更改。
通过添加等待期来延迟声明部分完成的工作(以允许先前的 engine 聚合),然后再处理部分完成的作业(将此与上述建议结合使用,大多数双引擎问题都应避免)。
接口¶
- class taskflow.jobs.base.JobPriority(value, names=<not given>, *values, module=None, qualname=None, type=None, start=1, boundary=None)[source]¶
基础:
Enum作业优先级的枚举(基于 hadoop 作业优先级建模)。
- VERY_HIGH = 'VERY_HIGH'¶
极其紧急的作业优先级。
- HIGH = 'HIGH'¶
轻微紧急的作业优先级。
- NORMAL = 'NORMAL'¶
默认作业优先级。
- LOW = 'LOW'¶
优先级较低的任务。
- VERY_LOW = 'VERY_LOW'¶
优先级非常低的任务。
- class taskflow.jobs.base.Job(board, name, uuid=None, details=None, backend=None, book=None, book_data=None)[source]¶
基类:
object表示一个命名的、可跟踪的工作单元的抽象类。
一个任务连接一个日志簿、一个所有者、一个优先级、最后修改和创建日期以及任务具有的任何相关状态。由于它连接到一个日志簿,而每个日志簿都与一组可以创建流程的工厂相关联,因此它是可以由实体拥有(通常该实体将读取这些日志簿并运行任何包含的流程)的工作单元的当前顶级容器。
在可预见的未来,将只允许一个实体拥有和操作一个任务中包含的流程。
注意(harlowja):此对象将在失败时传输到另一个实体,以便将包含的流程的所有权转移给第二个实体/所有者,以便恢复、继续、撤销…
- abstract property last_modified¶
任务最后修改的日期时间。
- abstract property created_on¶
任务创建的日期时间。
- property board¶
此任务发布或创建的看板。
- abstract property state¶
访问此任务的当前状态。
- abstract property priority¶
此任务的
JobPriority。
- wait(timeout=None, delay=0.01, delay_multiplier=2.0, max_delay=60.0, sleep_func=<built-in function sleep>)[source]¶
等待任务进入完成状态。
如果任务在给定的超时时间内未完成,则返回 false,否则返回 true(如果由于某种原因无法读取任务信息,则也可能引发任务失败异常)。定期状态检查将每
delay秒发生一次,其中delay将在找到未完成的状态后乘以给定的乘数。请注意,如果未提供超时时间,则相当于阻塞直到任务完成。 另外请注意,如果看板后端可以优化此方法,则其实现可能不会使用延迟(和退避) 。但是,无论应用了什么优化,实现都必须始终尊重给定的超时值。
- property book¶
与此任务关联的日志簿。
如果未与此任务关联日志簿,则此属性为 None。
- property book_uuid¶
与此任务关联的日志簿的 UUID。
如果未与此任务关联日志簿,则此属性为 None。
- property book_name¶
与此任务关联的日志簿的名称。
如果未与此任务关联日志簿,则此属性为 None。
- property uuid¶
此任务的 UUID。
- property details¶
与此任务关联的任何详细信息的字典。
- property name¶
此任务的非唯一标识名称。
- class taskflow.jobs.base.JobBoardIterator(board, logger, board_fetch_func=None, board_removal_func=None, only_unclaimed=False, ensure_fresh=False)[source]¶
基类:
object遍历看板的迭代器,遍历潜在的任务。
它提供以下属性
only_unclaimed:一个布尔值,指示是否仅遍历未认领的任务ensure_fresh:一个布尔值,要求每次获取新的任务集时,强制后端刷新(确保看板具有最新的任务列表)board:此迭代器创建的看板
- property board¶
此迭代器创建的看板。
- class taskflow.jobs.base.JobBoard(name, conf)[source]¶
基类:
object可以发布、重新发布、认领和转移任务的地方。
此看板可以有多种实现,具体取决于底层看板实现所需的语义和功能。
注意(harlowja):名称旨在类似于报纸或其他地方使用的公告牌/发布系统,用于征集人们可以面试和申请(然后工作和完成)的任务。
- abstract iterjobs(only_unclaimed=False, ensure_fresh=False)[source]¶
返回当前在此看板上的任务的迭代器。
注意(harlowja):迭代顺序应为发布顺序(从旧到新),优先级较高的任务应在优先级较低的任务之前提供,但由后端实现提供最适合它的顺序。
注意(harlowja):返回的迭代器可能支持其他属性,这些属性可用于进一步自定义迭代方式;请检查后端的迭代器对象以确定支持哪些其他属性。
- 参数:
only_unclaimed – 一个布尔值,指示是否仅遍历未认领的任务。
ensure_fresh – 一个布尔值,要求仅遍历最新的任务,其中“最新”的定义由后端特定。后端如果其内部语义/功能不支持此参数,则可以忽略此值。
- abstract wait(timeout=None)[source]¶
等待给定的时间,直到有任务发布。
找到任务后,将返回一个迭代器,该迭代器可用于遍历这些任务。
注意(harlowja):由于看板可以由多个外部实体同时修改,因此返回的迭代器可能为空,因为其他实体可能在创建迭代器后删除了这些任务(请注意在使用时这一点)。
- 参数:
timeout – 等待任务出现的时间(以秒为单位)(如果为 None,则永久等待)。
- abstract property job_count¶
返回此看板上的任务数量。
注意(harlowja):此计数可能会随着任务的出现或删除而变化,因此不应以需要精确和绝对的方式使用此计数的准确性。
- property name¶
此看板的非唯一标识名称。
- abstract consume(job, who)[source]¶
永久(且原子地)从看板中删除任务。
消耗向看板(以及任何其他检查看板的人)发出信号,表明此任务已由先前认领该任务的实体完成。
只有认领该任务的实体才能消耗该任务。
已消耗的任务不能被另一个实体认领或重新发布(任务发布是不可变的)。任何消耗未认领的任务(或他们没有认领权的任务)的实体都会引发异常。
- 参数:
job – 此看板上的一个任务,可以被消耗(如果不存在,则会引发 NotFound 异常)。
who – 执行消耗的实体的名称,必须与用于认领此任务的名称相同。
- abstract post(name, book=None, details=None, priority=JobPriority.NORMAL)[source]¶
原子地将任务创建并发布到看板。
此发布允许其他人尝试认领该任务(然后进行工作)。提供的日志簿、详细信息字典或名称(或这些的组合)的内容必须提供足够的用于引用和构建包含的工作的信息(无论是什么)。
一旦发布了任务,只能通过消费该任务(在任务被认领后)来将其移除。任何实体都可以向任务板发布/提议任务(未来这可能会受到限制)。
返回一个任务对象,代表发布的信息。
- abstract claim(job, who)[source]¶
原子性地尝试认领提供的任务。
如果一个任务被认领,预计认领该任务的实体将在未来的某个时间处理该任务的内容,并完成任务(导致重新发布)或从任务板消费该任务(表示其完成)。如果认领失败,将引发相应的异常来向认领尝试者发出信号。
- 参数:
job – 此任务板上可以认领的任务(如果不存在,将引发 NotFound 异常)。
who – 认领实体的名称字符串。
- abstract abandon(job, who)[source]¶
原子性地尝试放弃提供的任务。
此放弃信号告知其他人该任务现在可以被重新认领。通常,如果认领任务的实体未能或无法完成其先前认领的任务,则会发生这种情况。
只有认领了该任务的实体才能放弃任务。任何实体放弃未认领的任务(或他们不拥有的任务)都将导致异常。
- 参数:
job – 此任务板上可以放弃的任务(如果不存在,将引发 NotFound 异常)。
who – 执行放弃的实体的名称字符串,必须与认领此任务时使用的名称相同。
- abstract trash(job, who)[source]¶
丢弃提供的任务。
丢弃任务向其他人发出信号,该任务已损坏,不应被重新认领。这为用户提供了一种从外部将任务从板上删除的选项。丢弃的任务详细信息应保留在其他位置以供审查(如果需要)。
只有认领了该任务的实体才能丢弃任务。任何实体丢弃未认领的任务(或他们不拥有的任务)都将导致异常。
- 参数:
job – 此任务板上可以丢弃的任务(如果不存在,将引发 NotFound 异常)。
who – 执行丢弃的实体的名称字符串,必须与认领此任务时使用的名称相同。
- abstract register_entity(entity)[source]¶
将实体注册到任务板(的后端),例如:一个指挥者。
- 参数:
entity (
Entity) – 要注册为与任务板(的后端)关联的实体
- abstract property connected¶
返回此任务板是否已连接。
- class taskflow.jobs.base.NotifyingJobBoard(name, conf)[source]¶
Bases:
JobBoard一个可以通知其他人有关板事件的子任务板。
实现者预计至少会通知有关任务发布和删除的信息。
注意(harlowja):发出的通知可能会在单独的专用线程中发出,因此请确保注册的所有回调都是线程安全的(并且阻塞的时间尽可能短)。
- taskflow.jobs.backends.fetch(name, conf, namespace='taskflow.jobboards', **kwargs)[source]¶
获取具有给定配置的作业板后端。
此获取方法将在入口点命名空间中查找入口点名称,然后尝试使用提供的名称、配置和任何板特定的 kwargs 实例化该入口点。
注意(harlowja):为了便于指定配置和选项到板,配置(通常只是一个字典)也可以是一个标识入口点名称和该板特定配置的 URI 字符串。
例如,给定以下配置 URI
zookeeper://<not-used>/?a=b&c=d
这将查找名为“zookeeper”的入口点,并将由 URI 的组件组成的配置对象(在本例中为
{'a': 'b', 'c': 'd'})提供给该板实例的构造函数(包括指定的名称)。
实现¶
Zookeeper¶
- class taskflow.jobs.backends.impl_zookeeper.ZookeeperJob(board, name, client, path, uuid=None, details=None, book=None, book_data=None, created_on=None, backend=None, priority=JobPriority.NORMAL)[source]¶
Bases:
Job一个 zookeeper 任务。
- property lock_path¶
存储作业锁/认领和所有者 znode 的路径。
- property priority¶
此任务的
JobPriority。
- property path¶
存储作业数据 znode 的路径。
- property sequence¶
当前作业的序列号。
- property root¶
作业在 zookeeper 中的父路径。
- property last_modified¶
任务最后修改的日期时间。
- property created_on¶
任务创建的日期时间。
- property state¶
访问此任务的当前状态。
- class taskflow.jobs.backends.impl_zookeeper.ZookeeperJobBoard(name, conf, client=None, persistence=None, emit_notifications=True)[source]¶
Bases:
NotifyingJobBoard一个由 zookeeper 支持的任务板。
由 kazoo 库提供支持。
此任务板在 zookeeper 中的一个目录中创建序列化持久 znodes,并使用 zookeeper 监视来通知其他任务板使用
post()方法发布的作业(这会创建一个包含作业内容/详细信息编码在 json 中的 znode)。这些任务板的用户(可能在不相交的机器集合上)然后可以遍历可用的作业,并决定他们是否想要尝试认领他们遍历的作业中的一个。如果是这样,他们将尝试联系 zookeeper,他们将尝试使用持久 znode 的名称加上“.lock”作为后缀创建一个临时 znode。如果尝试使用claim()方法认领作业的实体能够创建具有该名称的临时 znode,则允许(并期望)执行该作业内容描述的任何工作。完成之后,临时 znode 和持久 znode 将在单个事务中删除(如果成功完成)。如果认领实体不成功(或认领该 znode 的实体死亡),则临时 znode 将被释放(手动使用abandon()或由 zookeeper 在临时节点和关联会话被认为丢失时自动释放)。请注意,kazoo 客户端的创建是通过
make_client()实现的,并且此任务板配置的传输到该函数以创建客户端可能发生在__init__时。这意味着此任务板配置中的某些参数可以提供给make_client(),以便如果调用者未提供客户端,则将根据make_client()的规范创建客户端。- MIN_ZK_VERSION = (3, 4, 0)¶
事务支持是在 3.4.0 中添加的,因此我们需要至少该版本。
- LOCK_POSTFIX = '.lock'¶
锁条目具有的 Znode 后缀。
- TRASH_FOLDER = '.trash'¶
根路径下创建的 Znode 子路径,包含已删除的作业。
- ENTITY_FOLDER = '.entities'¶
根路径下创建的 Znode 子路径,包含已注册的实体。
- JOB_PREFIX = 'job'¶
作业条目具有的 Znode 前缀。
- DEFAULT_PATH = '/taskflow/jobs'¶
用于作业的默认 Znode 路径(数据、锁等)。
- STATE_HISTORY_LENGTH = 2¶
要保留的先前状态更改的数量,主要用于历史记录跟踪和调试连接问题。
- NO_FETCH_STATES = ('LOST', 'SUSPENDED')¶
在这些状态下,从获取例程返回空列表的客户端状态,在此期间,基础连接正在恢复或可能恢复(即,它没有完全断开连接)。
- property path¶
所有作业 Znode 将存储的路径。
- property trash_path¶
所有已删除的作业 Znode 将存储的路径。
- property entity_path¶
所有 Conductor 信息 Znode 将存储的路径。
- property job_count¶
返回此看板上的任务数量。
注意(harlowja):此计数可能会随着任务的出现或删除而变化,因此不应以需要精确和绝对的方式使用此计数的准确性。
- iterjobs(only_unclaimed=False, ensure_fresh=False)[source]¶
返回当前在此看板上的任务的迭代器。
注意(harlowja):迭代顺序应为发布顺序(从旧到新),优先级较高的任务应在优先级较低的任务之前提供,但由后端实现提供最适合它的顺序。
注意(harlowja):返回的迭代器可能支持其他属性,这些属性可用于进一步自定义迭代方式;请检查后端的迭代器对象以确定支持哪些其他属性。
- 参数:
only_unclaimed – 一个布尔值,指示是否仅遍历未认领的任务。
ensure_fresh – 一个布尔值,要求仅遍历最新的任务,其中“最新”的定义由后端特定。后端如果其内部语义/功能不支持此参数,则可以忽略此值。
- post(name, book=None, details=None, priority=JobPriority.NORMAL)[source]¶
原子地将任务创建并发布到看板。
此发布允许其他人尝试认领该任务(然后进行工作)。提供的日志簿、详细信息字典或名称(或这些的组合)的内容必须提供足够的用于引用和构建包含的工作的信息(无论是什么)。
一旦发布了任务,只能通过消费该任务(在任务被认领后)来将其移除。任何实体都可以向任务板发布/提议任务(未来这可能会受到限制)。
返回一个任务对象,代表发布的信息。
- claim(job, who)[source]¶
原子性地尝试认领提供的任务。
如果一个任务被认领,预计认领该任务的实体将在未来的某个时间处理该任务的内容,并完成任务(导致重新发布)或从任务板消费该任务(表示其完成)。如果认领失败,将引发相应的异常来向认领尝试者发出信号。
- 参数:
job – 此任务板上可以认领的任务(如果不存在,将引发 NotFound 异常)。
who – 认领实体的名称字符串。
- consume(job, who)[source]¶
永久(且原子地)从看板中删除任务。
消耗向看板(以及任何其他检查看板的人)发出信号,表明此任务已由先前认领该任务的实体完成。
只有认领该任务的实体才能消耗该任务。
已消耗的任务不能被另一个实体认领或重新发布(任务发布是不可变的)。任何消耗未认领的任务(或他们没有认领权的任务)的实体都会引发异常。
- 参数:
job – 此看板上的一个任务,可以被消耗(如果不存在,则会引发 NotFound 异常)。
who – 执行消耗的实体的名称,必须与用于认领此任务的名称相同。
- abandon(job, who)[source]¶
原子性地尝试放弃提供的任务。
此放弃信号告知其他人该任务现在可以被重新认领。通常,如果认领任务的实体未能或无法完成其先前认领的任务,则会发生这种情况。
只有认领了该任务的实体才能放弃任务。任何实体放弃未认领的任务(或他们不拥有的任务)都将导致异常。
- 参数:
job – 此任务板上可以放弃的任务(如果不存在,将引发 NotFound 异常)。
who – 执行放弃的实体的名称字符串,必须与认领此任务时使用的名称相同。
- trash(job, who)[source]¶
丢弃提供的任务。
丢弃任务向其他人发出信号,该任务已损坏,不应被重新认领。这为用户提供了一种从外部将任务从板上删除的选项。丢弃的任务详细信息应保留在其他位置以供审查(如果需要)。
只有认领了该任务的实体才能丢弃任务。任何实体丢弃未认领的任务(或他们不拥有的任务)都将导致异常。
- 参数:
job – 此任务板上可以丢弃的任务(如果不存在,将引发 NotFound 异常)。
who – 执行丢弃的实体的名称字符串,必须与认领此任务时使用的名称相同。
- wait(timeout=None)[source]¶
等待给定的时间,直到有任务发布。
找到任务后,将返回一个迭代器,该迭代器可用于遍历这些任务。
注意(harlowja):由于看板可以由多个外部实体同时修改,因此返回的迭代器可能为空,因为其他实体可能在创建迭代器后删除了这些任务(请注意在使用时这一点)。
- 参数:
timeout – 等待任务出现的时间(以秒为单位)(如果为 None,则永久等待)。
- property connected¶
返回此任务板是否已连接。
Redis¶
- class taskflow.jobs.backends.impl_redis.RedisJob(board, name, sequence, key, uuid=None, details=None, created_on=None, backend=None, book=None, book_data=None, priority=JobPriority.NORMAL)[source]¶
Bases:
Job一个 Redis 作业。
- property key¶
作业数据存储在板列表/垃圾哈希中的键。
- property priority¶
此任务的
JobPriority。
- property last_modified_key¶
作业上次修改数据存储的键。
- property owner_key¶
作业声明 + 所有者数据存储的键。
- property sequence¶
当前作业的序列号。
- expires_in()[source]¶
声明到期需要多少秒。
返回声明条目到期的时间(秒),或者
DOES_NOT_EXPIRE或KEY_NOT_FOUND如果它不失效或如果无法确定失效时间(也许owner_key在查询时到期或之前到期?)。
- extend_expiry(expiry)[source]¶
延长此作业的拥有者密钥(即声明)的到期时间。
注意(harlowja):如果此作业的声明之前没有关联到期时间,则调用此方法将创建一个(并且在该时间过后,此作业上的声明将不再存在)。
如果请求到期成功,则返回
True,否则返回False。
- property created_on¶
任务创建的日期时间。
- property last_modified¶
任务最后修改的日期时间。
- property state¶
访问此任务的当前状态。
- class taskflow.jobs.backends.impl_redis.RedisJobBoard(name, conf, client=None, persistence=None)[source]¶
Bases:
JobBoard由 redis 支持的作业板。
由 redis-py 库提供支持。
这个任务板通过在 redis 哈希 中列出任务来创建任务条目。这个哈希包含可以由一组符合条件的消费者主动处理(和检查/声明)的任务。通常使用
post()方法发布任务(这会在 msgpack 中编码的任务内容/细节创建一个哈希条目)。这些任务板的用户(可能在不相交的机器集合上)可以迭代可用的任务,并决定是否尝试声明他们迭代过的任务中的一个。如果是,他们将尝试联系 redis,并尝试在 redis 中创建一个键(使用嵌入的 lua 脚本以原子方式执行此操作)以声明所需的任务。如果尝试使用任务板的实体能够创建该锁/所有者键来claim()任务,那么它将被允许(并且预计)执行该任务内容描述的任何工作。一旦声明实体完成,锁/所有者键和 哈希 条目将在单个请求中删除(也使用嵌入的 lua 脚本以原子方式执行此操作)(如果成功完成)。如果声明实体不成功(或者声明任务的实体崩溃),则锁/所有者键可以自动释放(通过**可选**使用声明过期时间)或通过使用abandon()手动放弃任务,以便其他人可以消费/处理它。注意(harlowja): 默认情况下,
claim()没有过期时间(这意味着声明即使在声明实体失败的情况下也是持久的)。要确保发生过期,请将一个数字值作为expiry关键字参数传递给claim()方法,该方法定义了声明应该保留的秒数。在使用过期时间时,请确保在使用extend_expiry()方法定期保持声明的存活状态,同时正在处理它。- CLIENT_CONF_TRANSFERS = (('host', <class 'str'>), ('port', <class 'int'>), ('username', <class 'str'>), ('password', <class 'str'>), ('encoding', <class 'str'>), ('encoding_errors', <class 'str'>), ('socket_timeout', <class 'float'>), ('socket_connect_timeout', <class 'float'>), ('unix_socket_path', <class 'str'>), ('ssl', <function bool_from_string>), ('ssl_keyfile', <class 'str'>), ('ssl_certfile', <class 'str'>), ('ssl_cert_reqs', <class 'str'>), ('ssl_ca_certs', <class 'str'>), ('db', <class 'int'>))¶
允许从任务板配置代理到 redis 客户端的键(以及值类型转换器)(如果未通过
client关键字参数显式提供客户端,则用于配置 redis 客户端内部)。参见: http://redis-py.readthedocs.org/en/2025.2/#redis.Redis
参见: https://github.com/andymccurdy/redis-py/blob/2.10.3/redis/client.py
- OWNED_POSTFIX = b'.owned'¶
用于创建任务所有者键的后缀(与任务键组合)。
- LAST_MODIFIED_POSTFIX = b'.last_modified'¶
用于创建任务最后修改键的后缀(与任务键组合)。
- DEFAULT_NAMESPACE = b'taskflow'¶
当未提供命名空间时,默认的键命名空间。
- MIN_REDIS_VERSION = (2, 6)¶
此后端所需的最低 redis 版本。
需要此版本,因为我们需要包含在 2.6 及更高版本中的内置服务器端 lua 脚本支持。
- NAMESPACE_SEP = b':'¶
用于将键与命名空间组合在一起(以获取将要使用的实际键)的分隔符。
- KEY_PIECE_SEP = b'.'¶
用于将许多键片段组合在一起(以获取将要使用的实际键)的分隔符。
- SCRIPT_STATUS_OK = 'ok'¶
调用成功时预期的 lua 响应状态字段。
- SCRIPT_STATUS_ERROR = 'error'¶
调用不成功时预期的 lua 响应状态字段。
- SCRIPT_NOT_EXPECTED_OWNER = 'Not expected owner!'¶
当所有者与预期不符时,预期的 lua 脚本错误响应。
- SCRIPT_UNKNOWN_OWNER = 'Unknown owner!'¶
当找不到所有者时,预期的 lua 脚本错误响应。
- SCRIPT_UNKNOWN_JOB = 'Unknown job!'¶
当找不到任务时,预期的 lua 脚本错误响应。
- SCRIPT_ALREADY_CLAIMED = 'Job already claimed!'¶
当任务已被声明时,预期的 lua 脚本错误响应。
- SCRIPT_TEMPLATES = {'abandon': '\n-- 提取 *所有* 变量 (以便 我们 可以 轻松 知道 它们 是什么)...\nlocal owner_key = KEYS[1]\nlocal listings_key = KEYS[2]\nlocal last_modified_key = KEYS[3]\n\nlocal expected_owner = ARGV[1]\nlocal job_key = ARGV[2]\nlocal last_modified_blob = ARGV[3]\nlocal result = {}\nif redis.call("hexists", listings_key, job_key) == 1 then\n if redis.call("exists", owner_key) == 1 then\n local owner = redis.call("get", owner_key)\n if owner ~= expected_owner then\n result["status"] = "${error}"\n result["reason"] = "${not_expected_owner}"\n result["owner"] = owner\n else\n redis.call("del", owner_key)\n redis.call("set", last_modified_key, last_modified_blob)\n result["status"] = "${ok}"\n end\n else\n result["status"] = "${error}"\n result["reason"] = "${unknown_owner}"\n end\nelse\n result["status"] = "${error}"\n result["reason"] = "${unknown_job}"\nend\nreturn cmsgpack.pack(result)\n', 'claim': '\nlocal function apply_ttl(key, ms_expiry)\n if ms_expiry ~= nil then\n redis.call("pexpire", key, ms_expiry)\n end\nend\n\n-- 提取 *所有* 变量 (以便 我们 可以 轻松 知道 它们 是什么)...\nlocal owner_key = KEYS[1]\nlocal listings_key = KEYS[2]\nlocal last_modified_key = KEYS[3]\n\nlocal expected_owner = ARGV[1]\nlocal job_key = ARGV[2]\nlocal last_modified_blob = ARGV[3]\n\n-- 如果 这个 是非数字的 (它 可能是 ),那么它将变成 nil\nlocal ms_expiry = nil\nif ARGV[4] ~= "none" then\n ms_expiry = tonumber(ARGV[4])\nend\nlocal result = {}\nif redis.call("hexists", listings_key, job_key) == 1 then\n if redis.call("exists", owner_key) == 1 then\n local owner = redis.call("get", owner_key)\n if owner == expected_owner then\n -- 所有者 相同,保持不变...\n redis.call("set", last_modified_key, last_modified_blob)\n apply_ttl(owner_key, ms_expiry)\n end\n result["status"] = "${error}"\n result["reason"] = "${already_claimed}"\n result["owner"] = owner\n else\n redis.call("set", owner_key, expected_owner)\n redis.call("set", last_modified_key, last_modified_blob)\n apply_ttl(owner_key, ms_expiry)\n result["status"] = "${ok}"\n end\nelse\n result["status"] = "${error}"\n result["reason"] = "${unknown_job}"\nend\nreturn cmsgpack.pack(result)\n', 'consume': '\n-- 提取 *所有* 变量 (以便 我们 可以 轻松 知道 它们 是什么)...\nlocal owner_key = KEYS[1]\nlocal listings_key = KEYS[2]\nlocal last_modified_key = KEYS[3]\n\nlocal expected_owner = ARGV[1]\nlocal job_key = ARGV[2]\nlocal result = {}\nif redis.call("hexists", listings_key, job_key) == 1 then\n if redis.call("exists", owner_key) == 1 then\n local owner = redis.call("get", owner_key)\n if owner ~= expected_owner then\n result["status"] = "${error}"\n result["reason"] = "${not_expected_owner}"\n result["owner"] = owner\n else\n -- 顺序 很重要 (首先 删除 所有者 ,如果\n -- 这 失败了,那么 作业数据 仍然 存在,因此 它可以\n -- 再次 处理,而不是 相反)... \n redis.call("del", owner_key, last_modified_key)\n redis.call("hdel", listings_key, job_key)\n result["status"] = "${ok}"\n end\n else\n result["status"] = "${error}"\n result["reason"] = "${unknown_owner}"\n end\nelse\n result["status"] = "${error}"\n result["reason"] = "${unknown_job}"\nend\nreturn cmsgpack.pack(result)\n', 'trash': '\n-- 提取 *所有* 变量 (以便 我们 可以 轻松 知道 它们 是什么)...\nlocal owner_key = KEYS[1]\nlocal listings_key = KEYS[2]\nlocal last_modified_key = KEYS[3]\nlocal trash_listings_key = KEYS[4]\n\nlocal expected_owner = ARGV[1]\nlocal job_key = ARGV[2]\nlocal last_modified_blob = ARGV[3]\nlocal result = {}\nif redis.call("hexists", listings_key, job_key) == 1 then\n local raw_posting = redis.call("hget", listings_key, job_key)\n if redis.call("exists", owner_key) == 1 then\n local owner = redis.call("get", owner_key)\n if owner ~= expected_owner then\n result["status"] = "${error}"\n result["reason"] = "${not_expected_owner}"\n result["owner"] = owner\n else\n -- 这个 顺序 很重要 (尝试 首先 移动 该值\n -- 并且 只有 这样 成功了,我们 才 尝试 进行任何删除)... \n redis.call("hset", trash_listings_key, job_key, raw_posting)\n redis.call("set", last_modified_key, last_modified_blob)\n redis.call("del", owner_key)\n redis.call("hdel", listings_key, job_key)\n result["status"] = "${ok}"\n end\n else\n result["status"] = "${error}"\n result["reason"] = "${unknown_owner}"\n end\nelse\n result["status"] = "${error}"\n result["reason"] = "${unknown_job}"\nend\nreturn cmsgpack.pack(result)\n'}¶
Lua 模板脚本,将被各种方法使用(它们在调用时被转换为真实脚本并加载到
connect()方法中)。需要注意的事项
lua 脚本是串行运行的,因此当此脚本运行时,没有其他命令会更改后端(redis 也确保没有其他脚本正在运行),因此这些脚本的原子性由 redis 保证。
考虑过事务(甚至大部分已经实现),但最终被拒绝,因为 redis 不支持回滚,并且事务 不能相互依赖(后续操作不能依赖于早期操作的结果)。这两个问题限制了我们正确报告错误(并提供有用的消息)以及在故障/争用情况下保持一致性的能力(由于无法回滚)。使用事务的第三个也是最终的打击是,为了正确使用它们,我们必须监视一个 非常有争议的键(listings 键),这会在负载下导致客户端更频繁地重试(这也会增加网络负载、使用的 CPU 周期、触发的事务失败等)。
由于
EXEC之前/之后的失败,部分事务执行是可能的(并且缺乏回滚使情况更糟)。
总的来说,在思考之后,似乎拥有小的 lua 脚本并不坏(即使它有些复杂),这归因于上述问题以及公开提到的关于事务的问题。通常使用 lua 脚本来实现这个目的似乎是一种常见的做法,并且它解决了在考虑和实现事务时出现的问题。
一些关于 redis(以及 redis + lua)的链接,可能对查看有用
- join(key_piece, *more_key_pieces)[source]¶
从多个片段创建并返回一个命名空间键。
注意(harlowja):所有文本/unicode 的片段都会被转换为其二进制等效值(如果它们已经是二进制则不进行转换),然后再进行连接(因为 redis 期望二进制键,而不是 unicode/文本键)。
- property namespace¶
所有键都将以此命名空间为前缀(或没有)。
- trash_key¶
一个哈希将存储在此键中,用于存储被丢弃的任务。
- sequence_key¶
一个整数将存储在此键中(用于序列化任务)。
- listings_key¶
一个哈希将存储在此键中,用于存储活动任务。
- property job_count¶
返回此看板上的任务数量。
注意(harlowja):此计数可能会随着任务的出现或删除而变化,因此不应以需要精确和绝对的方式使用此计数的准确性。
- property connected¶
返回此任务板是否已连接。
- post(name, book=None, details=None, priority=JobPriority.NORMAL)[source]¶
原子地将任务创建并发布到看板。
此发布允许其他人尝试认领该任务(然后进行工作)。提供的日志簿、详细信息字典或名称(或这些的组合)的内容必须提供足够的用于引用和构建包含的工作的信息(无论是什么)。
一旦发布了任务,只能通过消费该任务(在任务被认领后)来将其移除。任何实体都可以向任务板发布/提议任务(未来这可能会受到限制)。
返回一个任务对象,代表发布的信息。
- wait(timeout=None, initial_delay=0.005, max_delay=1.0, sleep_func=<built-in function sleep>)[source]¶
等待给定的时间,直到有任务发布。
找到任务后,将返回一个迭代器,该迭代器可用于遍历这些任务。
注意(harlowja):由于看板可以由多个外部实体同时修改,因此返回的迭代器可能为空,因为其他实体可能在创建迭代器后删除了这些任务(请注意在使用时这一点)。
- 参数:
timeout – 等待任务出现的时间(以秒为单位)(如果为 None,则永久等待)。
- iterjobs(only_unclaimed=False, ensure_fresh=False)[source]¶
返回当前在此看板上的任务的迭代器。
注意(harlowja):迭代顺序应为发布顺序(从旧到新),优先级较高的任务应在优先级较低的任务之前提供,但由后端实现提供最适合它的顺序。
注意(harlowja):返回的迭代器可能支持其他属性,这些属性可用于进一步自定义迭代方式;请检查后端的迭代器对象以确定支持哪些其他属性。
- 参数:
only_unclaimed – 一个布尔值,指示是否仅遍历未认领的任务。
ensure_fresh – 一个布尔值,要求仅遍历最新的任务,其中“最新”的定义由后端特定。后端如果其内部语义/功能不支持此参数,则可以忽略此值。
- consume(job, who)[source]¶
永久(且原子地)从看板中删除任务。
消耗向看板(以及任何其他检查看板的人)发出信号,表明此任务已由先前认领该任务的实体完成。
只有认领该任务的实体才能消耗该任务。
已消耗的任务不能被另一个实体认领或重新发布(任务发布是不可变的)。任何消耗未认领的任务(或他们没有认领权的任务)的实体都会引发异常。
- 参数:
job – 此看板上的一个任务,可以被消耗(如果不存在,则会引发 NotFound 异常)。
who – 执行消耗的实体的名称,必须与用于认领此任务的名称相同。
- claim(job, who, expiry=None)[source]¶
原子性地尝试认领提供的任务。
如果一个任务被认领,预计认领该任务的实体将在未来的某个时间处理该任务的内容,并完成任务(导致重新发布)或从任务板消费该任务(表示其完成)。如果认领失败,将引发相应的异常来向认领尝试者发出信号。
- 参数:
job – 此任务板上可以认领的任务(如果不存在,将引发 NotFound 异常)。
who – 认领实体的名称字符串。
Etcd¶
- class taskflow.jobs.backends.impl_etcd.EtcdJob(board: EtcdJobBoard, name, client, key, uuid=None, details=None, backend=None, book=None, book_data=None, priority=JobPriority.NORMAL, sequence=None, created_on=None)[source]¶
Bases:
Job一个 Etcd 任务。
- property last_modified¶
任务最后修改的日期时间。
- property created_on¶
任务创建的日期时间。
- property state¶
访问此任务的当前状态。
- property priority¶
此任务的
JobPriority。
- class taskflow.jobs.backends.impl_etcd.EtcdJobBoard(name, conf, client=None, persistence=None)[source]¶
Bases:
JobBoard一个由 etcd 支持的任务板。
这个任务板在 etcd 中创建序列化的键/值对。每个键代表一个任务,其关联的值包含以 json 编码的任务参数。任务板的用户可以迭代可用的任务,并决定是否通过调用
claim()方法尝试声明一个任务。声明任务包括原子地基于任务的键和“.lock”后缀创建一个键。如果该键的原子创建成功,则该任务属于该用户。任何尝试锁定已经锁定的任务都将失败。当任务完成时,用户通过调用consume()方法来消费任务,它从 etcd 中删除任务和锁。或者,如果用户想删除任务或将其留给另一个用户,可以丢弃 (trash()) 或放弃 (abandon())。Etcd 不提供解锁任务的方法,当消费者死亡时。Etcd 任务板提供基于全局ttl配置设置或claim()方法的expiry参数的定时过期。当达到此生存时间/过期时,该任务将自动解锁,并且另一个消费者可以声明它。如果预计任务的工作时间超过定义的生存时间,则消费者可以通过调用EtcdJob.extend_expiry()函数来刷新计时器。- property job_count¶
返回此看板上的任务数量。
- register_entity(entity: entity.Entity)[source]¶
注册一个实体到任务板(的后端),例如:一个调度器
- property connected¶
返回此任务板是否已连接。
层级¶